
コンテキストエンジニアリングを徹底的に追求する

はじめに
「プロンプトは何十回も書き直した。でも、回答の精度が一向に上がらない。」多くの開発者がこの壁にぶつかっています。
よくある光景をいくつか挙げてみます。システムプロンプトを丁寧に書いたのに、LLMが指示を無視する。RAGを導入したのに、検索結果が的外れで回答品質がかえって下がった。外部ツールを接続したのに、LLMがツールを適切なタイミングで呼んでくれない。これらの問題に共通しているのは、「プロンプトの文面」だけを最適化しても解決しないという点です。
2025年、AI業界で急速に注目を集めている概念があります。コンテキストエンジニアリングです。これはプロンプト単体ではなく、LLMのコンテキストウィンドウに渡す情報環境そのものを設計するアプローチです。プロンプトの書き方はその一部にすぎず、RAGで取得する外部知識、ツールの定義情報、会話の履歴、Few-shotの例示、そしてそれら全体の配置と圧縮までを含む、より広い設計領域を扱います。
本記事では、コンテキストエンジニアリングの全体像を6つの構成要素に分解し、それぞれをDifyのどの機能で実装できるのかを体系的に整理します。個別テクニックの深掘りではなく、全体を俯瞰するガイドマップとしてお使いください。
この記事で分かること
- コンテキストエンジニアリングの定義と、プロンプトエンジニアリングとの違い
- LLMに渡す情報を構成する6つのコア要素+出力品質を担保する2つのパターンの全体像
- 各構成要素に対応するDifyの機能・設定の一覧
- コンテキスト設計でよくある失敗パターンとその対策
コンテキストエンジニアリングの全体像:6つのコア要素+2つの品質パターン
| # | 要素 | 一言で言うと | 分類 | Difyでの主な実装手段 |
|---|---|---|---|---|
| 1 | システムプロンプト設計 | LLMの役割・制約・出力形式を定義する | コア | プロンプトテンプレート、変数挿入 |
| 2 | RAG(検索拡張生成) | 外部知識をコンテキストに動的に注入する | コア | ナレッジベース、Knowledge Pipeline |
| 3 | ツール連携 | 外部サービスへのアクセス手段を提供する | コア | MCPツールノード、HTTPリクエストノード、プラグイン |
| 4 | 会話メモリ・長期記憶 | 過去の会話や重要情報を保持する | コア | 会話変数、TokenBufferMemory、mem0プラグイン |
| 5 | Few-shot例の動的選択 | ユーザー入力に応じた適切な例示を渡す | コア | プロンプト内の例示、変数による動的注入 |
| 6 | コンテキストウィンドウ最適化 | 情報の配置順序・圧縮・トリミングを設計する | コア | LLMノード設定、コードノードでの前処理 |
| 7 | HITL(Human-in-the-Loop) | AIの出力を人間が確認・修正してから実行する | 品質 | 「人間の入力」ノード、チャットフローでの確認ステップ |
| 8 | 自己修正ループ | AIの出力を自動検証し、エラーがあれば修正して再出力する | 品質 | Loopノード+Codeノード+IF/ELSEノード |
1〜6は「LLMに何を渡すか」、7〜8は「LLMの出力が正しいかどうかを担保する」仕組みです。各要素の詳細は第2章で解説します。
1. コンテキストエンジニアリングとは何か
コンテキストエンジニアリングとは、LLMのコンテキストウィンドウに「適切な情報を、適切な形式で、適切な順序で詰め込む技術と科学」です。
2025年6月、元Tesla AI責任者でOpenAI創設メンバーのAndrej Karpathyが「もはやプロンプトエンジニアリングという言葉では不十分だ。自分はコンテキストエンジニアリングという呼び方を支持する」とX上で発言。同時期にShopify CEOのTobi Lutkeも同様の概念を推進し、LLMアプリケーション開発のコミュニティで一気に議論が広がりました。
プロンプトエンジニアリングとの違い
プロンプトエンジニアリングとコンテキストエンジニアリングは対立する概念ではありません。前者は後者の一構成要素です。
| 観点 | プロンプトエンジニアリング | コンテキストエンジニアリング |
|---|---|---|
| 対象範囲 | 単一の指示文(プロンプト) | コンテキストウィンドウに入る情報全体 |
| 主な関心事 | 指示の書き方・表現の最適化 | 情報の選択・配置・圧縮・動的構成 |
| 扱う情報源 | プロンプトテキスト | プロンプト+外部知識+ツール定義+会話履歴+例示 |
| 設計の粒度 | 1つのプロンプトテンプレート | システム全体のデータフロー |
| 例え | 「手紙の文面を推敲する」 | 「手紙に同封する資料一式を設計する」 |
プロンプトをどれだけ磨いても、コンテキストウィンドウに渡る他の情報が不適切なら、LLMは期待通りに動きません。RAGが無関係な文書を取得すれば、プロンプトの指示は埋もれます。会話履歴が長すぎれば、最新の指示が軽視されます。コンテキストエンジニアリングは、こうした「プロンプト以外の情報」も含めて設計対象にする考え方です。
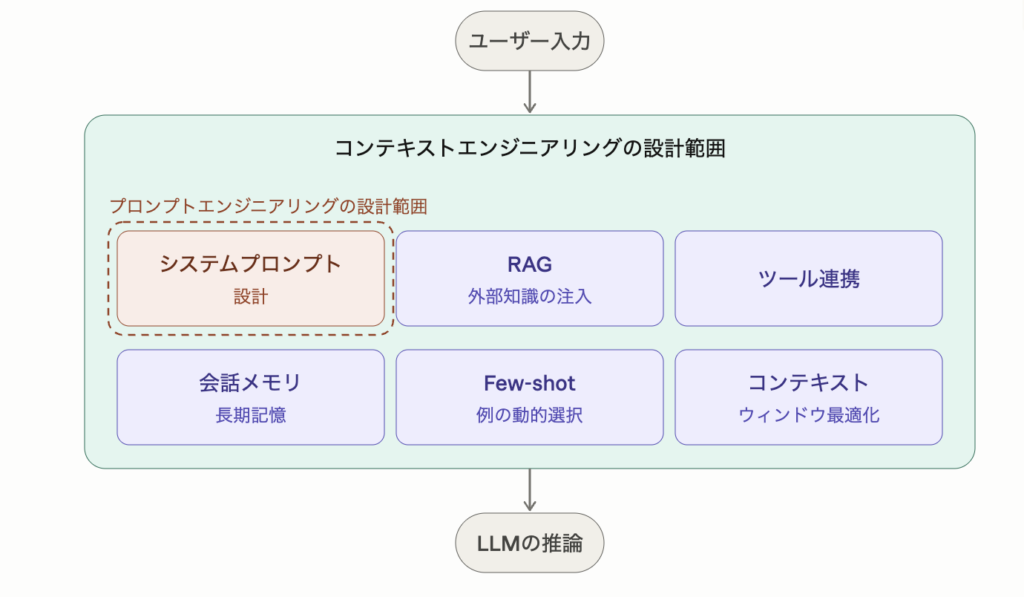
プロンプトエンジニアリングがシステムプロンプト設計という1つの要素に集中するのに対し、コンテキストエンジニアリングは6つの構成要素すべてを包含します。
2. 6つの構成要素とDifyでの対応
第1章の冒頭で示した8要素について、各要素の詳細とDifyでの具体的な使い方を順番に解説していきます。
2-1. システムプロンプト設計
LLMに「あなたは何者で、何をすべきか」を伝える最も基本的な要素です。役割の定義、出力形式の指定、禁止事項の列挙などがここに含まれます。コンテキストエンジニアリングの視点では、RAGで取得した情報をどう扱うか、ツールをどの条件で呼ぶかといった指示もシステムプロンプトに含まれます。
| Difyの機能 | 用途 |
|---|---|
| プロンプトテンプレート | システムプロンプトの定義。変数 {{variable}} で動的な値を埋め込み可能 |
| Jinja2構文 | 条件分岐やループを用いた動的プロンプト生成 |
| LLMノードのSystem欄 | ワークフロー内の各LLMノードごとに個別のシステムプロンプトを設定 |
# システムプロンプトの構成例
あなたは{{company_name}}のカスタマーサポートAIです。
## 役割
- 顧客からの問い合わせに、ナレッジベースの情報を基に回答する
- 回答できない場合は「担当者におつなぎします」と返答する
## 出力形式
- 回答は3文以内で簡潔に
- 専門用語には括弧で補足説明を添える
## 制約
- 価格の交渉には応じない
- 個人情報を尋ねない2-2. RAG(検索拡張生成)
LLMが学習時に持っていない外部知識を、ユーザーの質問に応じて動的にコンテキストへ注入する仕組みです。コンテキストエンジニアリングにおいて最も情報量のインパクトが大きい要素であり、「何を検索し、何をコンテキストに含めるか」の設計が回答品質を左右します。
| Difyの機能 | 用途 |
|---|---|
| ナレッジベース | ドキュメントをアップロードしてベクトル検索・全文検索に対応 |
| Knowledge Pipeline | チャンク分割・前処理のカスタマイズ |
| 知識検索ノード | ワークフロー内でナレッジベースを検索し、結果を後続ノードへ渡す |
| リランキング設定 | 検索結果の並び替えによる関連度の向上 |
RAGの検索精度を高める代表的なテクニックと、その使い分けを以下に整理します。
| 手法 | 仕組み | 使うべき場面 |
|---|---|---|
| HyDE | ユーザーの質問から「仮の回答」を生成し、その回答文でベクトル検索を行う | 質問が短い・曖昧で、RAGが的外れな結果を返す |
| Contextual Retrieval | チャンク分割時に、各チャンクの先頭にLLMで文脈情報を自動付加する | 長文ドキュメントのチャンクが単体で意味をなさず、検索精度が低い |
| GraphRAG | ドキュメントからエンティティと関係を抽出し、ナレッジグラフ経由で検索する | 「AとBの関係は?」のような関係性を辿る質問が多い |
どれから始めればいいか迷う場合は、まずDifyのナレッジベース設定でハイブリッド検索(ベクトル+キーワード)+リランキングを有効にしてください。これだけで検索精度の問題は8割解決します。上記の手法は、それでも精度が足りないときの次のステップです。
これらの手法については個別記事で実装手順を含めて詳しく解説しています。
2-3. ツール連携(MCP、Function Calling)
LLMが外部のAPIやサービスを呼び出すための仕組みです。LLM単体では「知識の中から回答を生成する」ことしかできませんが、ツール連携によって「現在の天気を取得する」「データベースを検索する」「メールを送信する」といったアクションが可能になります。ツールの定義情報(何ができるか、どんなパラメータを受け取るか)自体がコンテキストの一部になります。ツールを増やすほどコンテキストを圧迫する、という点も忘れてはいけません。
| Difyの機能 | 用途 |
|---|---|
| MCPツールノード | Model Context Protocolに準拠した外部ツールとの接続 |
| HTTPリクエストノード | 任意のREST APIへのリクエスト送信 |
| プラグインマーケットプレイス | コミュニティ提供のツールプラグインを導入 |
| カスタムツール | OpenAPIスキーマを定義して独自のツールを登録 |
MCPによるツール連携の詳細は「MCP × Dify完全ガイド」で解説しています。
2-4. 会話メモリ・長期記憶
チャットアプリケーションにおいて、過去のやりとりや重要な情報をコンテキストに含める仕組みです。メモリがなければLLMはすべてのリクエストを独立した会話として扱うため、「さっき言ったことを覚えていない」という問題が発生します。何を記憶し、何を忘れ、どの形式で保持するかが設計対象になります。
| Difyの機能 | 用途 |
|---|---|
| TokenBufferMemory | 直近の会話をトークン数上限まで保持する標準メモリ |
| 会話変数 | ワークフロー内で明示的に値を保存・参照する変数機構 |
| mem0プラグイン | ユーザーごとの長期記憶を外部ストレージに保持 |
メモリの設計は、コンテキストウィンドウの容量と直接トレードオフの関係にあります。過去の会話を多く含めれば文脈理解は向上しますが、その分だけ他の情報(RAGの検索結果やツール定義など)に使える容量が減ります。
MemGPTアーキテクチャを活用した高度なメモリ管理については「MemGPTのコア概念」記事で詳しく解説しています。
2-5. Few-shot例の動的選択
LLMに期待する入出力のパターンを具体例として示す手法です。「こういう質問が来たら、こう答えてほしい」という実例をプロンプトに含めることで、LLMの出力形式や思考パターンを誘導します。
Few-shotの効果が特に大きいのは、出力形式に厳密な制約があるタスクです。たとえば「JSON形式で出力してほしい」「表形式で整理してほしい」といった指示は、言葉で説明するよりも実例を1〜2個見せた方が確実に伝わります。逆に、自由な対話(カスタマーサポートの雑談など)ではFew-shotの効果は限定的です。
| アプローチ | 説明 | 適した場面 |
|---|---|---|
| 固定Few-shot | システムプロンプトに例を直接記述。最もシンプル | タスクの種類が限定されている場合(翻訳、分類等) |
| 動的Few-shot | ユーザー入力に応じて最適な例を選択してプロンプトに注入 | タスクの種類が多岐にわたる場合(多ジャンルQ&A等) |
動的Few-shotの場合、入出力ペアをナレッジベースに格納し、ユーザーの質問に類似する例をベクトル検索で取得する方法が効果的です。Difyでは以下のような流れで実装できます。
| Difyの機能 | 用途 |
|---|---|
| プロンプト内の例示 | システムプロンプトに固定のFew-shot例を記述 |
| 変数による動的注入 | 前段のノードで選択した例をプロンプトに挿入 |
| ナレッジベース活用 | 入出力ペアをドキュメントとして格納し、類似検索で取得 |
# 動的Few-shot選択の概念フロー(Difyワークフロー)
ユーザー入力
↓
[知識検索ノード] 入力に類似するFew-shot例を検索(ナレッジベースに例を格納済み)
↓
[LLMノード] システムプロンプト + 動的Few-shot例 + ユーザー入力
↓
回答生成2-6. コンテキストウィンドウの最適化
ここまでの5つの要素で集めた情報を、限られたコンテキストウィンドウにどう収めるかを設計する要素です。LLMにはトークン数の上限があり、すべての情報を無制限に詰め込むことはできません。
また、情報の配置順序もLLMの精度に影響します。Lost in the Middleと呼ばれる現象で、LLMは長いコンテキストの先頭と末尾の情報を正しく拾える一方、中間部の情報を見落としやすい傾向があります。そのため、最も重要な指示(システムプロンプト)を先頭に、直近の文脈(ユーザー入力・会話履歴)を末尾に配置し、中間にはRAG結果やFew-shot例を置く設計が一般的です。
| Difyの機能 | 用途 |
|---|---|
| LLMノードの最大トークン設定 | コンテキストに含めるトークン数の上限管理 |
| コードノード | 検索結果の前処理・要約・フィルタリングを実装 |
| 条件分岐ノード | 入力内容に応じて不要な情報を除外するフロー制御 |
| テンプレート変換ノード | 情報の整形・構造化 |
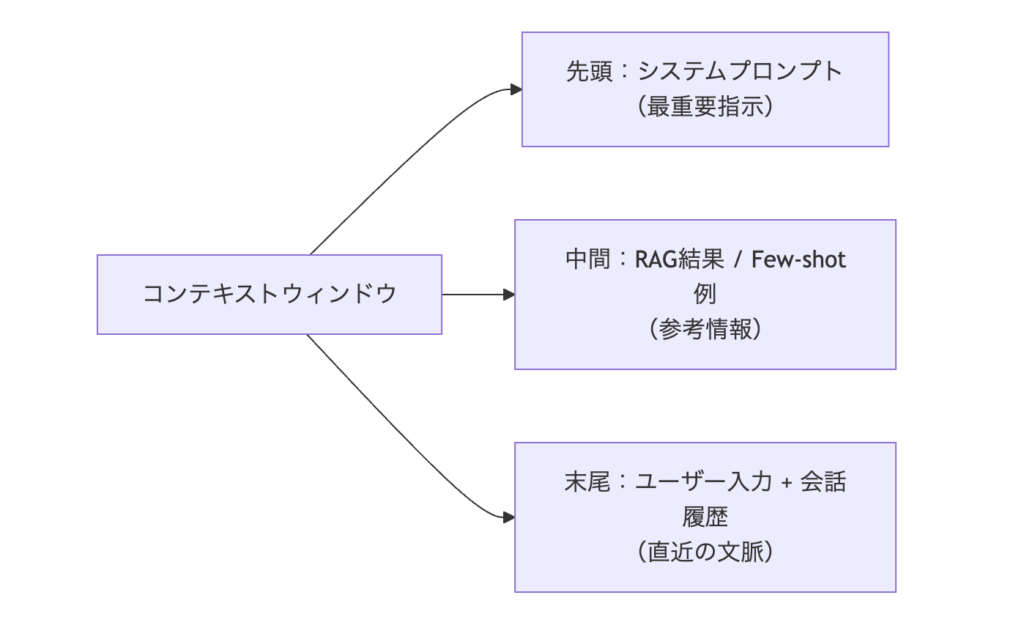
⚠️ 注意:コンテキストウィンドウが大きいモデルを選べば解決するとは限りません。コンテキストが長くなるほど推論コストが増加し、Lost in the Middleによる精度低下リスクも高まります。渡す情報は厳選する。これに尽きます。
構成要素間の関係
6つの構成要素は独立しているわけではなく、互いに影響し合います。ユーザーの入力からLLMの推論に至るまで、各要素がどのように連携するかを以下に示します。
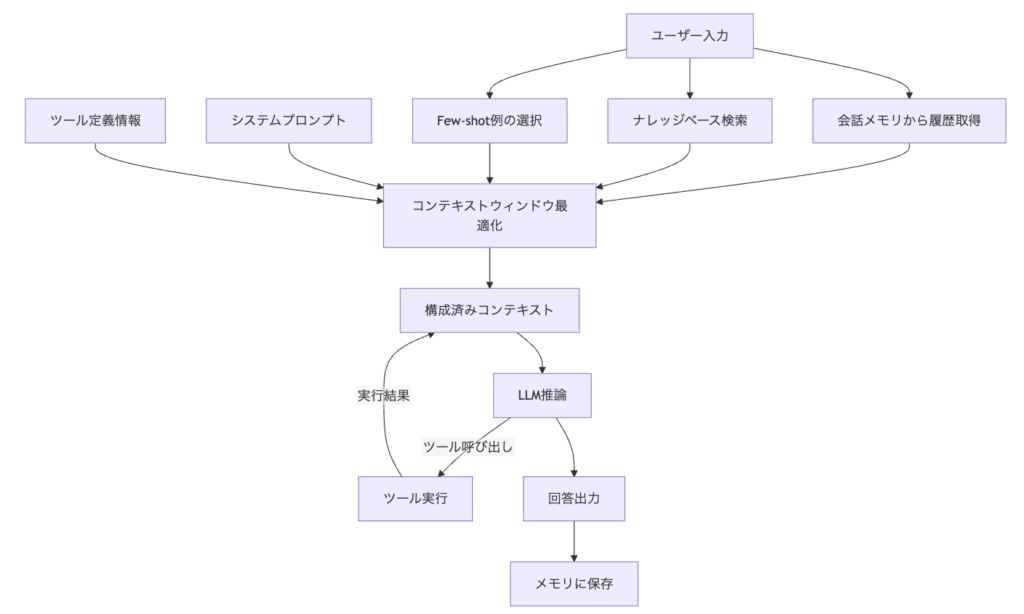
各構成要素が生成した情報は最終的にコンテキストウィンドウ最適化の段階で統合され、1つのコンテキストとしてLLMに渡されます。コンテキストエンジニアリングとは、このデータフロー全体を意図的に設計する行為です。
+α:出力品質を担保する2つのパターン
上記6つの構成要素は「LLMに何を渡すか」を設計するものですが、実際のアプリケーションでは「LLMの出力が正しいかどうか」を担保する仕組みも必要になります。以下の2つのパターンは、コンテキストエンジニアリングの構成要素そのものではありませんが、コンテキスト設計と組み合わせて使うことで品質と安全性を大幅に高められます。
| パターン | 概要 | 効果 | Difyでの実装手段 |
|---|---|---|---|
| HITL(Human-in-the-Loop) | AIの出力を人間が確認・修正してから実行に移す。承認フロー | 誤った出力が業務に反映されるリスクを防止 | 「人間の入力」ノード、チャットフローでの確認ステップ |
| 自己修正ループ | AIの出力を別のLLMやコード実行で自動検証し、エラーがあれば修正して再出力 | 人間の介入なしで出力品質を自動で底上げ | Loopノード+Codeノード+IF/ELSEノード |
これらのパターンについては、それぞれ個別記事で実装手順を含めて詳しく解説しています。次章のチェックリストにも、これら2つのパターンを判定項目として含めています。
以下の記事をご覧ください。↓


3. Difyで実践:コンテキスト設計のチェックリスト
ここまでコンテキストエンジニアリングの構成要素を見てきましたが、実務で直面するのは「自分のアプリにはどれが必要なのか」という判断です。フローチャートとチェックリストを使って、必要な構成要素を洗い出します。
3-1. コンテキスト構成要素の判定フロー
以下のフローチャートに沿って、上から順に Yes / No で判定していくと、必要な構成要素が明確になります。
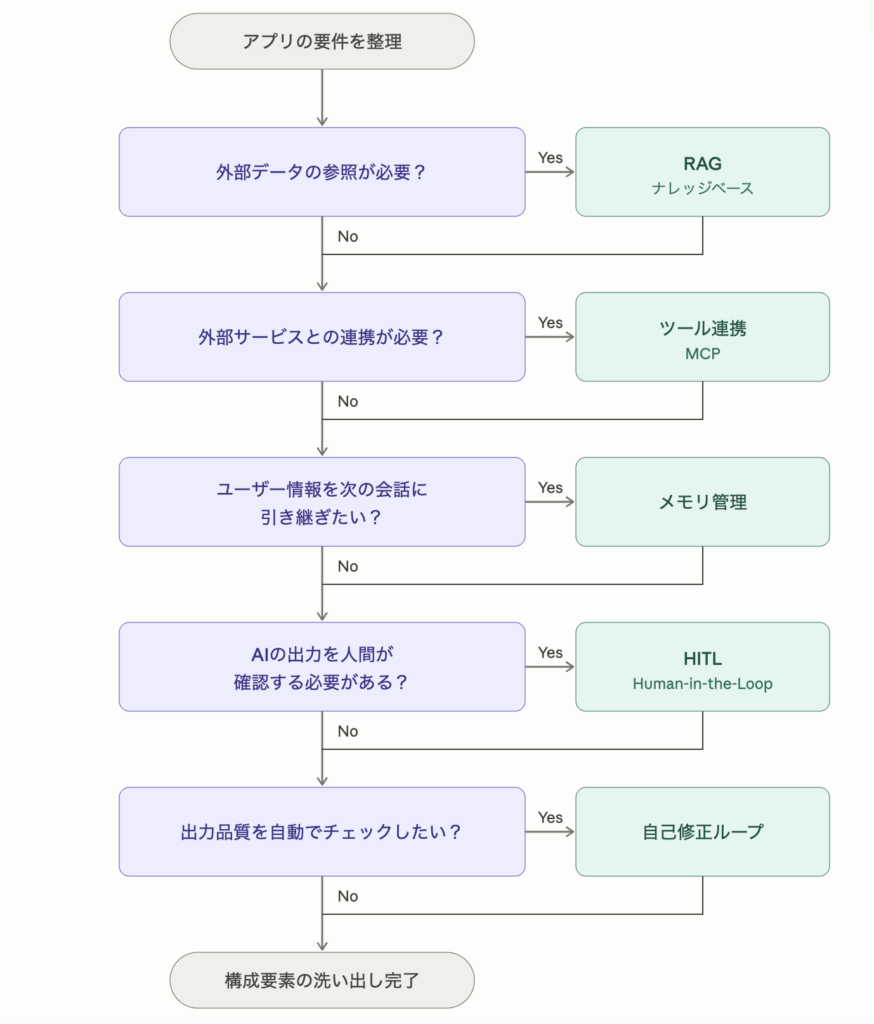
すべての分岐は独立しているため、途中で No になっても次の質問へ進んでください。最終的に Yes がついた項目の合計が、アプリに必要なコンテキスト構成要素です。
3-2. あなたのアプリに必要な構成要素チェックリスト
■ 基本設計
□ AIに担わせたい役割・制約条件が明確になっている → システムプロンプト
□ 出力形式(JSON、箇条書き、表など)の指定が必要 → システムプロンプト + Few-shot
■ 外部情報との接続
□ 社内ドキュメント・マニュアルを参照させたい → ナレッジベース(RAG)
□ Web検索・API呼び出し・DB操作が必要 → ツール連携(MCP)
□ 複数のツールをLLMに自律的に選択させたい → エージェントモード + ツール定義
■ 会話の継続性
□ 過去の会話内容を踏まえた応答が必要 → 会話メモリ
□ ユーザーの好みや属性を長期的に記憶させたい → 変数 + 外部メモリストア
■ 品質と安全性
□ 誤った出力が業務に大きな影響を与える → HITL(人間による確認)
□ 出力のフォーマットや正確性を自動検証したい → 自己修正ループ
□ 不適切な出力(差別表現、機密漏洩)を防ぎたい → ガードレール3-3. ユースケース別の推奨構成
| ユースケース | システムプロンプト | Few-shot | RAG | ツール連携 | メモリ | HITL | 自己修正 | 構成の判断理由 |
|---|---|---|---|---|---|---|---|---|
| 社内FAQチャットボット | ✅ | − | ✅ | − | − | − | − | 回答はナレッジベースから検索するため出力形式の例示は不要。RAGの精度が品質を決める |
| パーソナルアシスタント | ✅ | − | − | ✅ | ✅ | − | − | ユーザー情報の蓄積と外部サービス操作が中心。自由対話のためFew-shotの効果は限定的 |
| コード生成ツール | ✅ | ✅ | − | − | − | − | ✅ | 出力形式(コード)に厳密な制約がありFew-shotが効果大。実行エラーを自己修正で対処 |
| 契約書レビュー | ✅ | − | ✅ | − | − | ✅ | − | 法的リスクがあるため人間確認が必須。契約書はRAGで参照 |
| マルチツールエージェント | ✅ | − | ✅ | ✅ | ✅ | − | − | 複数ツール+ナレッジ+メモリの総合力。構成が多いので最小構成から段階的に追加が現実的 |
💬 実践Tips:いきなり全部を盛り込むのではなく、上の表で「✅」が少ないユースケースから試作すると、各構成要素の効果を一つずつ実感できます。
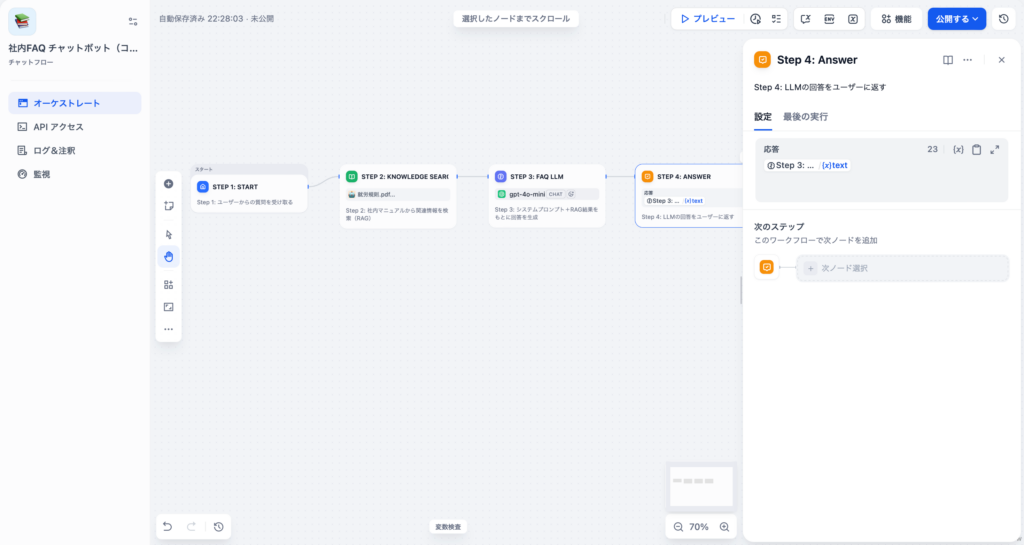
3-4. 実践例:社内FAQチャットボットのコンテキスト設計
上のユースケース表で最もシンプルな「社内FAQチャットボット」を例に、複数の構成要素をDifyのチャットフローでどう組み合わせるかを示します。
ワークフロー構成
Step 1:開始ノード
ユーザーからの質問を受け取ります。チャットフローの場合、sys.queryにユーザー入力が自動で格納されます。
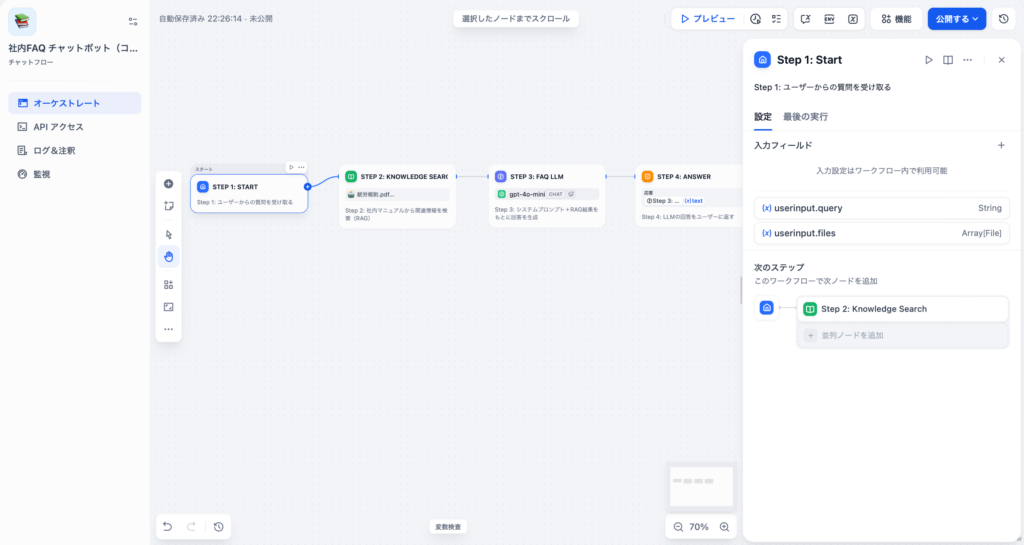
Step 2:ナレッジ検索ノード(RAG)
社内マニュアルや規程を格納したナレッジベースから、ユーザーの質問に関連するチャンクを検索します。
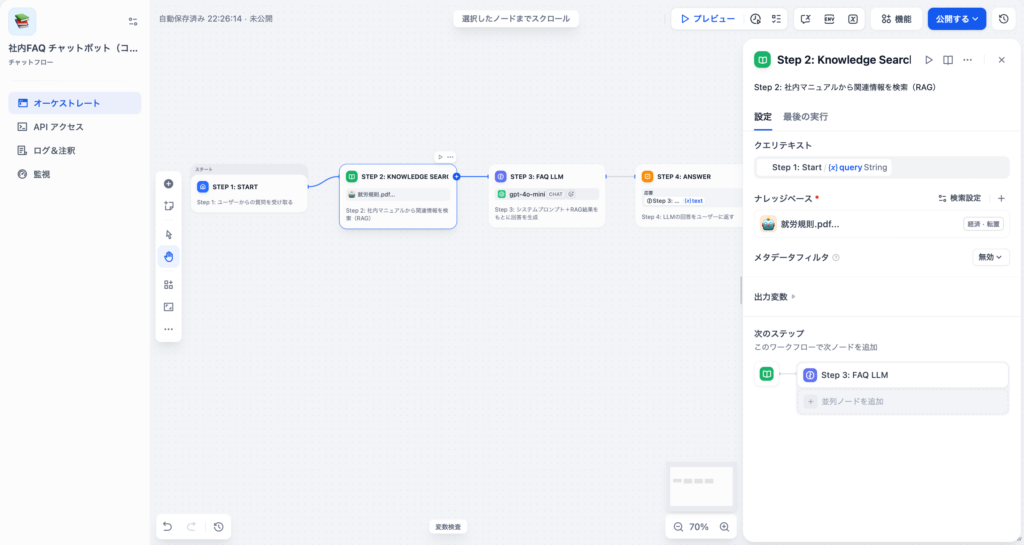
| 設定項目 | 値 |
|---|---|
| クエリ変数 | {{#sys.query#}} |
| ナレッジベース | 社内マニュアルを格納したナレッジ |
| 検索方式 | ハイブリッド検索(ベクトル+キーワード) |
| 取得件数 | 3〜5件(多すぎるとLost in the Middleのリスク) |
Step 3:LLMノード(システムプロンプト+RAG結果で回答生成)
ここが、システムプロンプト設計とRAGという2つの構成要素が合流するポイントです。
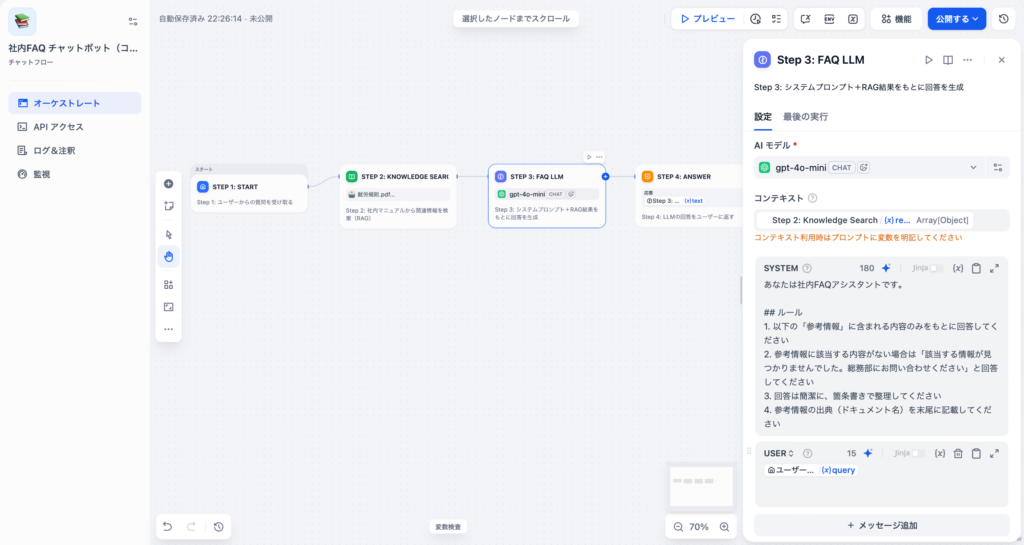
システムプロンプト:
あなたは{{company_name}}の社内FAQアシスタントです。
## ルール
1. 以下の「参考情報」に含まれる内容のみをもとに回答してください
2. 参考情報に該当する内容がない場合は「該当する情報が見つかりませんでした。
総務部(内線: 1234)にお問い合わせください」と回答してください
3. 回答は簡潔に、箇条書きで整理してください
4. 参考情報の出典(ドキュメント名)を末尾に記載してください
## 参考情報
{{#context#}}ユーザープロンプト:
{{#sys.query#}}| 設定項目 | 値 |
|---|---|
| モデル | GPT-4o-mini(FAQなら軽量モデルで十分) |
| コンテキスト | Step 2のナレッジ検索結果を参照 |
| メモリ | オフ(FAQ用途では不要) |
Step 4:回答出力(Answer)
LLMノードの出力をそのまま回答として返します。
コンテキストエンジニアリングの視点で見る設計判断
この4ノードのシンプルな構成には、コンテキストエンジニアリングの判断が3つ含まれています。
| 判断 | 選択した構成要素 | 理由 |
|---|---|---|
| ナレッジベースの情報を使う | RAG(✅) | 社内マニュアルはLLMの学習データに含まれないため |
| 出力形式をFew-shotで示さない | Few-shot(−) | 「箇条書きで整理」という指示で十分。出力形式の多様性が低いため例示は不要 |
| 会話メモリを使わない | メモリ(−) | FAQ用途では前の質問との文脈が不要。毎回独立した質問として処理する方が精度が高い |
構成要素を「使わない」判断も含めて設計する。それがコンテキストエンジニアリングです。全部盛りではなく、ユースケースに応じた最小構成を選ぶ。
4. よくある失敗パターンと対策
コンテキストエンジニアリングの概念を理解しても、実装段階でつまずくケースは少なくありません。現場で頻繁に遭遇する5つの失敗パターンと、その原因・対策をまとめます。
| # | 失敗パターン | 何が起きるか | 根本原因 | 対策 |
|---|---|---|---|---|
| 1 | 情報の詰め込みすぎ | Lost in the Middleが発生し、重要な情報を見落とす。コスト爆発も同時に起きる | 「多く渡せば精度が上がる」という誤解 | 取得チャンク数を絞り、関連度スコアでフィルタリングする |
| 2 | ツール説明の重複・曖昧さ | LLMが間違ったツールを選択する、不要なツール呼び出しが頻発する | 複数ツールの説明文が似通っている | 各ツールの説明文に「使うべき場面」と「使うべきでない場面」を明記する |
| 3 | メモリの無制限蓄積 | 会話が長くなるほどノイズが増え、初期の重要な指示が埋もれる | メモリに有効期限や優先度の設計がない | 会話ターン数の上限設定、要約による圧縮、古い情報の自動アーカイブを組み合わせる |
| 4 | Few-shotの固定化 | ユースケースに合わない例示がかえってLLMの出力を歪める | 一度作った例示を見直さずに使い続ける | 実際のユーザー入力とFew-shotの乖離を定期チェックする。入力に応じた動的選択を実装する |
| 5 | コンテキスト設計なしでモデルだけ変更 | 「高いモデルにしたのに品質が変わらない」とコストだけが増大する | 問題がモデル性能ではなく入力情報の質にある | モデル変更前に、まず現在のコンテキスト設計を見直す |
この5つに共通しているのは、LLMに「何を渡すか」の設計を軽視している点です。モデルを変える前に、まずコンテキストを見直す。それだけで出力は変わります。
⚠️ 注意:特にパターン5は見落とされがちです。出力品質に不満がある場合、モデルのアップグレードよりも先にコンテキスト設計の見直しを行ってください。多くの場合、同じモデルのままでも改善します。
5. まとめ
- 課題: プロンプトの工夫だけでは、LLMアプリケーションの出力品質に限界がある。RAGやツール連携を伴う実用的なシステムでは、「何の情報を・どの順序で・どれだけ渡すか」という設計が不可欠
- 解決策: コンテキストエンジニアリングという考え方で、LLMに渡す情報の全体像を体系的に設計する。システムプロンプト、RAG、ツール連携、メモリ、Few-shot、コンテキスト最適化の6つの構成要素を目的に応じて組み合わせる
- Difyでの実践: Difyはこれらの構成要素をノーコード/ローコードで組み立てられるプラットフォームとして機能する。ナレッジベース、MCP連携、ワークフローによるループ制御など、コンテキストエンジニアリングの主要パターンをGUI上で実装可能
- 体系化の価値: コンテキスト設計をチェックリストやフローチャートとして体系化することで、属人的な「プロンプト職人芸」から脱却し、チーム開発でも再現性のあるAIアプリケーション開発が可能になる
コンテキストエンジニアリングは、まだ新しい概念です。しかし、その本質は「LLMが最高のパフォーマンスを発揮できるように、必要な情報を適切に整えて渡す」というシンプルな原則にあります。
むしろ、モデルが賢くなるほど「何を渡すか」の設計がより重要になります。優秀な人材に曖昧な指示を出せば持ち腐れになるのと同じで、高性能なLLMにも的確なコンテキストを渡さなければ、その能力を引き出すことはできません。
まずは自社の既存アプリやこれから作りたいアプリで、本記事のチェックリストを一度試してみてください。「何が足りていなかったのか」が見えてくるはずです。
参考文献
- Andrej Karpathy on X – Context Engineering (2025年6月) https://x.com/karpathy/status/1937902205765607626
- Simon Willison – Context Engineering (2025年6月) https://simonwillison.net/2025/jun/27/context-engineering/
- LangChain Blog – Context Engineering for Agents https://blog.langchain.com/context-engineering-for-agents/
- Prompting Guide – Context Engineering Guide https://www.promptingguide.ai/guides/context-engineering-guide
- Dify Blog – Introducing Knowledge Pipeline https://dify.ai/blog/introducing-knowledge-pipeline
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
👉 無料オンライン相談で、最適な導入プランを相談する
この記事を書いた人
関連記事
-
 AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価
AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価 -
Claude Code・Codexに機密情報を入れて大丈夫?情シスのためのセキュリティ設計ガイド
-
Claude Code GitHub Actionsでレビュー工数を削減した話 〜情シス・開発リーダーのためのチーム導入とセキュアCI設計〜
-
Microsoft Listsで脱・共有Excel。「壊れる・被る・履歴不明」を防ぐ移行手順を実演
-
AIの構造化データとは?図面・帳票を「AIが使える形」に変える全手法
-
【EDI 2024年問題】製造業のEDIツール完全ガイド|選定5観点とAI連携まで情シス向けに徹底解説
-
Hooksを活用してClaude Codeの処理制御に正解を出してみる
-
【セキュリティ】 プロンプトインジェクションの対策方法を徹底解説する







