
「MoA」という手法で最高精度のLLM出力をノーコードで構築する

はじめに
「生成AIで最高の結果を出したいけれど、GPT-5.4、Claude Sonnet 4、Gemini 3.1 Pro、、、結局どのモデルを選べばいいの?」
そんなAI選定の悩みを根本から覆す最新アプローチが「MoA(Mixture-of-Agents)」です。
MoAとは、複数の異なるAIモデルにタスクを同時並行で解かせ、最終的に別の優秀なAIが統合・評価して最高の回答を生成する仕組みです。単独モデルの「思考の偏り」や「ハルシネーション」の問題に、複数の視点で相互補完するアプローチです。
本記事では、基礎概念の整理からノーコードツール「Dify」を使ったMoAワークフローの実際の構築手順まで解説します。
💡 この記事で分かること
- MoAの強み:なぜ1つのモデルより、異なるAIのチーム(GPT × Claude × Gemini)の方が優れた出力になるのか
- Difyでの構築手順:Parallelノードで複数AIを並列実行し、アグリゲーターにまとめさせる設定方法
2. MoA(Mixture-of-Agents)とは?Difyで実現するAI並列処理の基本
MoA(Mixture-of-Agents)は、複数の異なるAIモデルを連携させ、お互いの長所を生かして短所をカバーし合うアプローチです。
Together AIの研究チームらが発表した論文『Mixture-of-Agents Enhances Large Language Model Capabilities』においても、「複数のオープンソースモデルによるMoA構成が、単独のGPT-4oのスコアを上回った」という検証結果が出るなど、実務レベルでも大きな注目を集めています。
単一のLLMには「思考の偏り(バイアス)」と「見落とし・嘘(ハルシネーション)」という構造的限界があります。
モデルごとにアーキテクチャや学習データの偏りがあり、1つのモデルで進めると「思考の癖」に引き張られます。また複雑な要件ではハルシネーション(自信満々な誤情報)のリスクも伴います。
| モデル | 開発元 | 得意な領域 | 癖となりやすい側面 |
|---|---|---|---|
| GPT-5.4 | OpenAI | 論理的構造化・指示遵守・コーディング | バズワードに寄りがち、手堅い楽観性 |
| Claude Sonnet 4 | Anthropic | 長文執筆・安全性考慮・法的リスクの指摘 | 保守的・リスク回避寄りの提案が少なくなる |
| Gemini 3.1 Pro | 最新情報の取り込み・データ分析・実務指向 | 実験的提案が多い一方、深い哲学的考察が弱い |
MoAはこれら「異なる癖」を組み合わせて相互補完させることで、単一モデルの限界を越えます。
2.1 MoAの基本アーキテクチャ:「提案者」と「集約者」
MoAは、この限界を「複数のAIで一斉にアイデアを出し合い、最後にリーダー役AIが客観的にまとめる」というアプローチによって解決します。構成要素は大きく2つの役割に分けることができます。
- プロポーザー(Proposers:提案者たち)
「GPT-5.4」「Claude Sonnet 4」「Gemini 3.1 Pro」など、異なるエンジンを搭載した複数のモデル群です。これらがユーザーの同じタスクに対して、それぞれ完全に独立した回答(提案)を同時並行で作成します。 - アグリゲーター(Aggregator:集約者 / 最終決定者)
評価や論理的統合に最も長けた、強力な1つのモデル(例:GPT-5.4やClaude Sonnet 4など)です。プロポーザーたちが出した「全パターンの回答」を読み込み、それぞれの長所を拾い上げ、情報の抜け漏れを補完し合い、矛盾点を削ぎ落として、最も洗練された最終回答を生成します。
イメージとしては「専門分野の異なる3人の専門家に、それぞれ別室で独立してレポートを書かせ、最後に優秀な編集長が一本にまとめる」仕組みです。「1+1の答えは?」と問うと差が出ませんが、「来期の戦略とは?」と問うと、論理派・創造派・現実派それぞれの視点の違ったレポートが集まり、編集長がそれを統合することで圧倒的に厚みのある成果物が出来上がります。
3. 単一AIモデルの「3つの限界」とMoAによる解決
単独のLLMに業務を任せる従来の手法には、大きく分けて「思考の偏り」「ハルシネーション(嘘)」「性能の頭打ち」という3つの避けられない限界が存在します。MoAは複数モデルをオーケストレーションすることでこれらに対処しますが、ハルシネーションについては「なくす」のではなく「モデルごとに異なるハルシネーションを矛盾として検知しやすくする」というアプローチを取ります(アグリゲーター自体もLLMのため、完全な排除は保証されません)。
| 期待できる効果 | 従来の課題(単一モデルの限界) | MoAの革新的なアプローチ(解決策) |
|---|---|---|
| 「多角的な視点」と網羅性の獲得 | 汎用的なアイデアしか出ず、そのLLM特有のコンテキストに偏った思考になりがちだった。 | A社モデルの論理性、B社モデルの創造性、C社モデルの専門的視点が「良いとこ取り」で融合し、より実用的で多角的なアイデアが出力されます。 |
| ハルシネーションを「矛盾」として検知しやすくする | モデルが嘘をついた際、それに気づく手段が人間の目視による精査しかなかった。 | モデルごとに異なるハルシネーションは、他モデルの回答と矛盾する形で表面化されるため、アグリゲーターが「矛盾」として検知しやすくなります。 |
| 単体性能の限界突破 | どんなに優れたプロンプトを書いても、現行最強モデルの物理的な能力が「天井」になっていた。 | 特性の異なる複数モデルを並べ、優秀なモデルで統合することで、現状のトップモデル単体が叩き出せる限界スコアを物理的にブレイクスルーできます。 |
💡 具体的な使用例
- 重要文書の作成・企画立案: 複数モデルにブレストさせ、アグリゲーターに「矛盾のない完璧な企画書」にまとめさせる。
- コードレビュー: セキュリティ、パフォーマンス、可読性のそれぞれの観点に特化させたプロンプトを個別のAIに持たせ、最後にテックリードAIが総合的なレビューコメントをまとめる。
- 高精度な多言語翻訳: 複数の翻訳エンジン(DeepLベース、LLMベース等)の出力結果を突き合わせ、最も自然で適切なニュアンスの翻訳を一つ導き出す。
4. DifyでMoAを構築する手順【Parallelノード設定〜アグリゲーターまで】
MoAの実装には「同時に複数のLLMを叩く並列処理」が不可欠です。これをプログラムで書こうとすると非同期処理の実装が面倒ですが、Difyのワークフロー機能を使えば、コーディング不要のGUI上で「Parallel(並列)」ノードを直感的に配置するだけで簡単に実現できます。
今回は、「GPT-5.4」「Claude Sonnet 4」「Gemini 3.1 Pro」の3モデルを並列稼働(プロポーザー)させ、最後に「GPT-5.4」で統合(アグリゲーター)するフローを作ります。
ワークフロー全体像
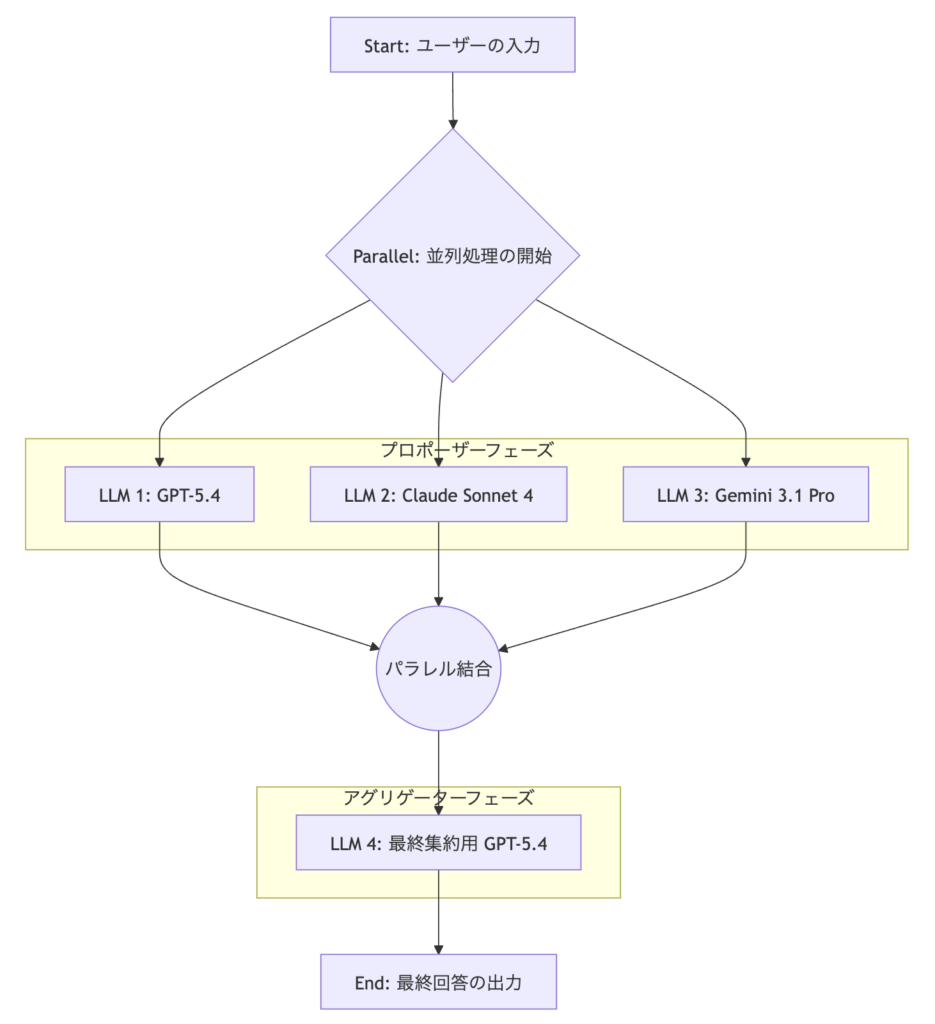
Step 1:StartノードとParallelノードの設定(並列展開)
- Startノード: ユーザーの入力を受け取るため、変数として
sys.query(テキスト)を設定します。 - Parallelノードの追加: Startノードの次には、処理を枝分かれさせるための
Parallelノードを配置します。これにより、3つのLLMへの問い合わせが同時に行われ、合計の待ち時間を劇的に短縮できます。
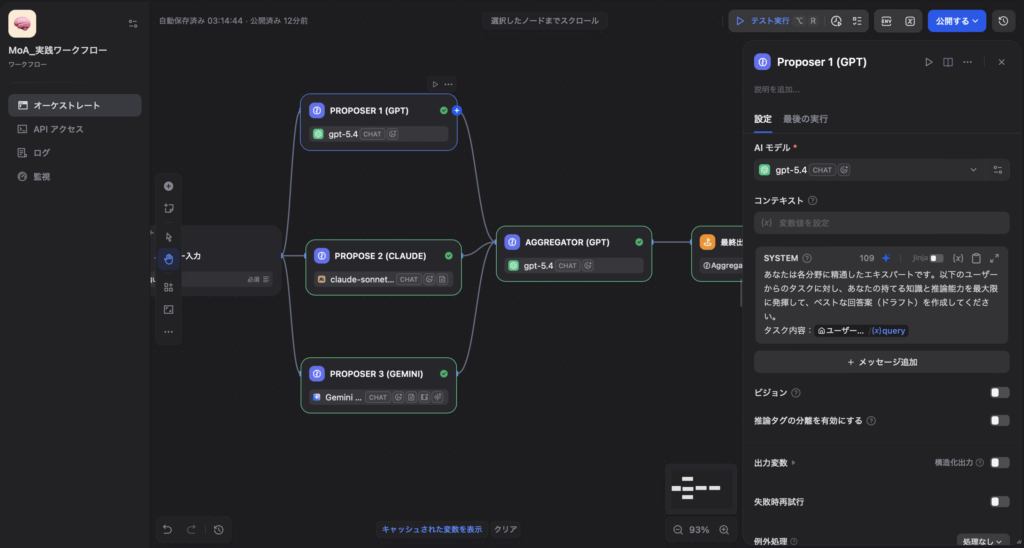
Step 2:複数モデル(Proposers)の設定(提案フェーズ)
Parallelノードから3つの分岐を作り、それぞれに LLMノード を配置します。MoAの真髄は「多様性」にあるため、あえて異なるベンダーのモデルを選択します。
- LLM 1:
GPT-5.4(OpenAI) - LLM 2:
Claude Sonnet 4(Anthropic) - LLM 3:
Gemini 3.1 Pro(Google)
【プロンプト設計(INSTRUCTION)】
入力を Start / sys.query にマッピングし、それぞれに提案を行わせます。
あなたは各分野に精通したエキスパートです。以下のユーザーからのタスクに対し、あなたの持てる知識と推論能力を最大限に発揮して、ベストな回答案(ドラフト)を作成してください。
タスク内容:{{sys.query}}💡 Tips: プロポーザーに「ペルソナ」を強制するとさらに効果的(詳細は第5章)
各LLMに「批判的なレビュアー」「突飛なアイデアを出すクリエイター」「現実的なPM」といった役割を指定することで、回答がさらに立体的になります。
Step 3:アグリゲーター(Aggregator)の設定(集約フェーズ)
3つのプロポーザーからの出力が終わると、Difyのシステム上で自動的にパラレルノードが結合されます。
その次に、すべての意見を取りまとめる「総監督」としてのLLMノードを配置します。
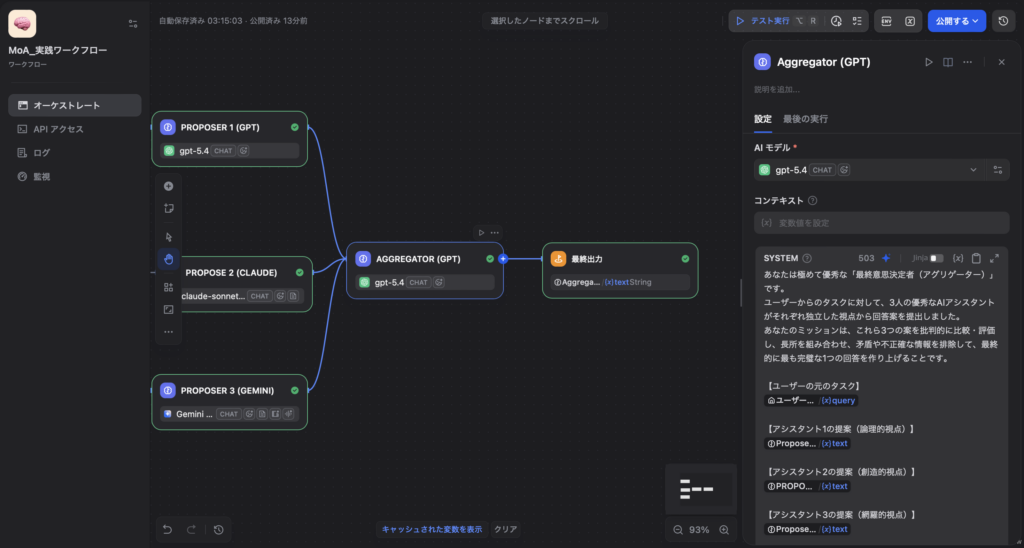
- モデル選定: 推論・統合・コンテキスト理解能力が最も高いモデル(最新の推論特化型モデルやGPT-5.4など)を指定します。
- プロンプト設計(INSTRUCTION): ここがMoAの品質を決定づける最重要ポイントです。3つのLLMの出力結果(
LLM1.text,LLM2.text,LLM3.text)を変数として渡し、厳格な統合ルールを与えます。
あなたは極めて優秀な「最終意思決定者(アグリゲーター)」です。
ユーザーからのタスクに対して、3人の優秀なAIアシスタントがそれぞれ独立した視点から回答案を提出しました。
あなたのミッションは、これら3つの案を批判的に比較・評価し、長所を組み合わせ、矛盾や不正確な情報を排除して、最終的に最も完璧な1つの回答を作り上げることです。
【ユーザーの元のタスク】
{{sys.query}}
【アシスタント1の提案(論理的視点)】
{{LLM1.text}}
【アシスタント2の提案(創造的・構造的視点)】
{{LLM2.text}}
【アシスタント3の提案(網羅的視点)】
{{LLM3.text}}
【統合のための厳守ルール】
1. 3つの提案の「良いとこ取り」をし、情報が最もリッチで網羅的な構成にすること。
2. もし3者間で意見の対立や事実の矛盾がある場合は、最も論理的に正しいと推論されるものを採用すること。
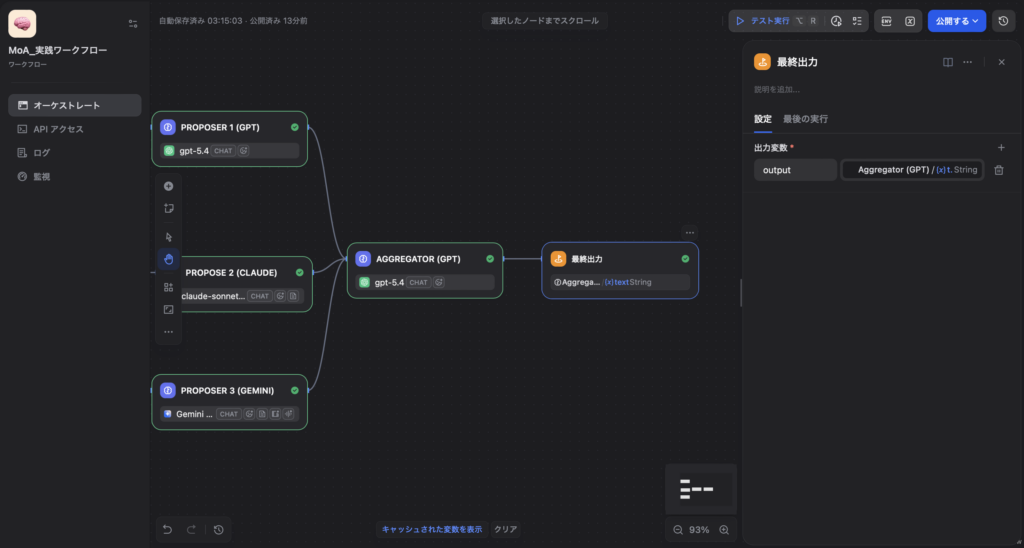
3. アシスタント1, 2, 3の言及(例:「提案1によると〜」など)は一切出さず、ユーザーに直接提出できる洗練された単一の成果物のみを出力すること。Step 4:Endノードの接続(最終出力)
アグリゲーターの出力(text)を Endノード の出力変数にマッピングして完成です。
実行テストを行うと、裏側で3つのAIが知恵を絞り、最後にアグリゲーターが圧倒的な説得力を持つ文書を一気に書き上げるプロセスを体験できます。
5. さらに高度な使い方:「役割分担(ロールベースMoA)」の実装
MoAのポテンシャルを極限まで引き出す最適解は、「プロポーザー(提案用LLM)ごとに明確な役割(ペルソナ)と異なる指示を割り当てる」ことです。
ここまで「全員に同じ質問を解かせる」シンプルな基本形を解説しましたが、より高度な現場では、各AIに異なる視点を強制させて意図的に白熱した議論を巻き起こします。
🔹 なぜ役割を分けるのか?
モデルを選ぶだけでも多様性は生まれますが、プロンプトで「視点」を明示的に強制することで、人間が思いつかない死角を網羅的にカバーできます。
🔹 実践例:新規事業の壁打ちワークフロー
例えば、ユーザーが「新規事業のアイデア」を入力した場合、3つのLLMノードのプロンプト(指示内容)を以下のように全く別のものに書き換えます。
- LLM 1(クリエイター): 「あなたは独創的なアイデアマンです。入力されたテーマについて、常識にとらわれない奇抜なアイデアを3つ出してください。」
- LLM 2(批評家・監査役): 「あなたは厳しい外資系コンサルタントです。入力されたテーマの事業リスク、法的課題、想定される失敗パターンを徹底的に洗い出してください。」
- LLM 3(プロジェクトマネージャー): 「あなたは現実主義のエンジニア兼PMです。入力されたテーマを実現するための最短のロードマップと、必要なリソース要件を箇条書きで定義してください。」
🔹 アグリゲーター(集約者)への指示の工夫
役割を分担させた場合、最後にすべてをまとめるアグリゲーター(GPT-5.4など)のプロンプトを以下のように設定します。
あなたは事業責任者です。
クリエイターからの『アイデア』、監査役からの『リスク分析』、PMからの『実行計画』が提出されました。
これらを統合し、リスクを回避しつつ独創的なアイデアを実現する、現実的かつ魅力的な『新規事業の企画書』をひとつ完成させてください。このように、「モデルの違い × プロンプトでの役割付け」を組み合わせることで、Dify内に「仮想の経営会議・開発チーム」を丸ごと構築することができます。これが、並列処理とMoAを組み合わせた一番面白い使い方と言えます。
【基本形 vs ロールベースMoA の使い分け】
| 比較項目 | 基本形MoA(全員に同じ質問) | ロールベースMoA(役割分担) |
|---|---|---|
| 向いているタスク | コーディング・翻訳・データ抜き(正解が存在する) | 新規企画・ブレスト・設計レビュー(正解がない) |
| プロンプトの設定 | 全LLMに共通の汎用プロンプトを使用 | LLMごとに「批判家」「クリエーター」「PM」など異なる役割を付与 |
| 期待する効果 | モデル固有のハルシネーションを「矛盾」として浮かび上がらせる | 届かなかった視点の発見・アイデアの拡散 |
| 設定難易度 | 簡単(プロンプトを共通化するだけ) | 設計が必要(各役割のプロンプトを個別に作り込む) |
6. 実践編:MoAの真価を引き出す3つのユースケースと出力比較
MoAの効果が最も顕著に出るのは、「唯一の正解がなく、多角的な視点が必要なテーマ」や「複雑なトレードオフが発生するテーマ」です。
- ① 新規企画やブレスト(アイデアの拡散)
- 質問例:「日本の地方都市にある空き家を活用して、Z世代向けに全く新しいビジネスを立ち上げたいです。考えられるビジネスモデルを5つ提案して」
- なぜ差が出るか:GPTは「コワーキング」等の手堅い論理を好み、Claudeは「コミュニティづくりや心理的安全性」にフォーカスしやすく、Geminiは「データ活用や最新トレンド」を絡めがちです。これらを統合することで分厚い企画書になります。
実際の出力比較:
▼ GPT-5.4(単一モデル)の出力結果
① クリエイター滞在型シェアハウス(制作×発信)
② 地方×推し活拠点(聖地化ビジネス)
③ ソーシャルワーケーションハウス(ゆるく働く)
④ 空き家×体験型サブスク(複数拠点ホッピング)
⑤ 地方課題解決DAOハウス(Web3×リアル)
→ クオリティは高いですが、「推し活」「ワーケーション」「DAO」など、流行り言葉(バズワード)の組み合わせに寄ってしまう「AI特有の手癖」が見えます。
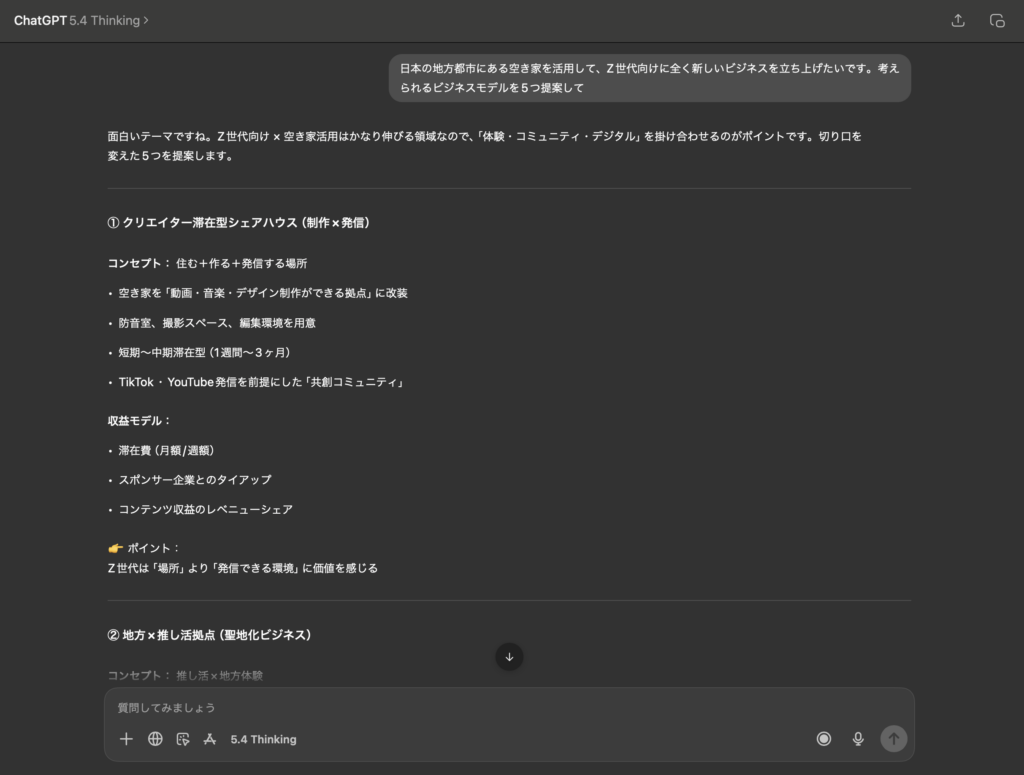
▼ MoA(GPT-5.4 × Claude Sonnet 4 × Gemini 3.1 Pro)の出力結果
1. クリエイター特化型「コンテンツファクトリー・コリビング」(GPT案を実用的に昇華)
2. 「デジタルデトックス × 深い集中」のサバティカル・リトリート(インサイトを突いた深い精神性)
3. サステナブル・アップサイクル工房(廃材を活用したD2C開発拠点)
4. ニッチ・コミュニティの秘密基地(特定の趣味を持つ層が深く繋がる会員制の場)
5. デジタルスキルを活用した「地方創生×リスキリング・エクスチェンジ」(スキルと体験のバーターモデル)
→ 各AIの強みが調和し、「サステナブル」「デジタルデトックス」など、バズワードではない本質的なインサイトを突いた高次元のビジネスプランへと昇華されます。

- ② 致命的なリスクの洗い出し(レビュー・監査)
- 質問例:「明日、社運を賭けた新しいAIアプリをリリースします。想定される『最悪の失敗経路』と、法務・技術・炎上のリスクを思いつく限り批判的に洗い出してください」
- なぜ差が出るか:各社のAIは安全基準のチューニングが異なります。Claudeは「法的・社会的なリスク」に非常に敏感であり、GPTは「システムのダウンタイム」などインフラ構造面を指摘しやすいため、多角的なリスク管理を一網打尽にできます。
- ③ 未知の問題に対するアプローチ(複雑なトラブルシューティング)
- 質問例:「先月から解約率が急激に悪化しています。システムエラーはない場合、どこから調査すべきか仮説を立てて」
- なぜ差が出るか:正解が見えない課題に対し、GPTは「マーケティングのフレームワーク(3Cや4P)」に沿って手順を組みがちですが、Geminiは「Google Analyticsでどの動線で離脱したか見ろ」と実務寄りの指示を出しがちです。
❌ 逆に「差が出にくい(MoAの無駄遣いになる)」質問
- 事実検索:「2020年のオリンピック開催地は?」
- 定型的なコード生成:「Pythonでcsvを読み込むスクリプトを書いて」
- 単純な要約:「このニュース記事を3行でまとめて」
【「MoAを使うべきか?」判断表】
| タスクの種類 | MoAの導入 | 理由 |
|---|---|---|
| 新規企画・初期アイデア出し | ✅ 最適 | 多角的な視点でアイデアが豊かになる |
| 重要文書(契約書・要件定義書)の作成 | ✅ 適切 | 抜け漏れや論理エラーを互いに指摘できる |
| コードレビュー(安全性・品質・性能) | ✅ 適切 | 各角度からの専門的なレビューが可能 |
| リスク・デビルズアドボケイトの作成 | ✅ 適切 | 各社のAIは安全基準のチューニングが異なり盲点を補完できる |
| 単純なFAQ回答(決まりきった問答) | ❌ 不要 | 複数回答を統合するまでもない |
| 事実検索(日付・定義の確認) | ❌ 不要 | 正解は1つだけで多角度は意味ない |
| 単純な要約・簡単な作業 | ❌ 不要 | 1モデルで等しくこなせる作業にコストをかける無駄 |
7. MoA導入時のコスト・レイテンシ問題と実運用での対処法
MoAは強力な手法ですが、現場に導入する場合はいくつか現実的なトレードオフを理解しておく必要があります。
7.1 避けて通れない「コスト(API料金)とレイテンシの増大」
1回のユーザーリクエストに対し、裏側では最低でも「(並列)モデル数 + アグリゲーター」のAPIコールが発生します。
【具体的なAPIコストの概算比較】
※入力指令1,000トークン、出力1,000トークンとして、最新ハイエンドモデル(GPT-5.4, Claude Sonnet 4等)の平均API単価で計算
- ✅ 単一モデル(GPT-5.4のみ):約2.5円 / 回
- 🚨 MoA(3モデル並列 + GPT-5.4で統合):約10.5円 / 回
- 内訳 : 提案モデル3つのAPI利用料(およそ計7.5円)+ アグリゲーターのAPI利用料(3人分の生成テキストを大容量コンテキストとして読み込み・統合するため単価が高くなり、約3円)
このように、今回の実践例の構成だとコストが通常の約4〜5倍に跳ね上がります(実際のAPIではプロンプトキャッシング機能によって計算上より安く済むケースもあります)。1回の実行ではたかだか数円の違いですが、数千・数万回稼働するカスタマーサポート機能などに組み込むと、思わぬコスト増を招きます。
また、アグリゲーターが長大なコンテキストを全て読み込んでから生成を開始するため、ユーザーの画面に結果が表示されるまでの初回トークン出力待ち時間(TTFT:Time to First Token)も長くなります。
- 対策:ルーティング(条件分岐)との併用
すべての質問をMoAに投げるのはコストの無駄です。Difyの中央に「Question Classifier(質問分類)」ノードを挟み、簡単な挨拶や日常的な質問は即座に単発のLLMへ流し、「複雑な要件定義、長文生成、正確性がクリティカルに求められるタスク」の場合のみMoAループへ分岐させる設計が実運用でのベストプラクティスです。
7.2 プロポーザー(提案者)の「多様性」が命
同じモデルを複数並べるより、OpenAI・Anthropic・Googleなど開発思想が異なるベンダーのモデル、あるいはLlama 3・Mistralなどのオープンソースモデルを組み合わせることで、MoAの真価である「視点の多様性」が最大限に発揮されます。
7.3 高度な発展形:「自己修正(Self-Correction)」との夢のコラボレーション
MoAの手法だけでもかなり実用的な出力が得られますが、さらに質を求める場合、前回の記事で紹介した「自己修正(Self-Correction)ループ」と組み合わせることも可能です。

MoAで生成したコードや文章をそのまま出力するのではなく「検証用LLM」に一度通し、エラーや抜け漏れが検知された場合のみ、MoAの回路へ再入力させてリファクタリングさせる、、、といった、「ミスを自分で見つけて直す、強固なAIチーム」をDify上に作ることもできます。
8. よくある質問:Dify × MoA の疑問を解決
Q. 提案者(プロポーザー)の数はいくつが最適ですか?
A. 精度とコストのバランスから、「3〜5モデル」程度が推奨されます。研究によれば、モデル数を増やしすぎても一定数を超えると性能の統合効果(マージン)が薄れ、単にAPIコストと待機時間が増幅するだけになることが分かっています。
Q. アグリゲーター(集約者)に選ぶべきモデルは?
A. 最も重要なポジションであるため、論理的推論力と長文のコンテキスト理解に優れた現行世代の最上位モデル(GPT-5.4 や Claude Sonnet 4 など)を配置してください。
Q. Difyの無償版でも作成できますか?
A. 作成は可能ですが、1回のアクションで複数回のLLM呼び出しを行うため、Difyクラウドの無料メッセージ枠(LLM利用枠)を猛烈な勢いで消費します。実運用や頻繁なテストを行う場合は、ご自身のAPIキー(OpenAI / Anthropic / Googleなど)を各プロバイダー設定に登録して利用することを強く推奨します。
9. まとめ
本記事では、複数モデルの叡智を結集させ、AIの限界を突破する「MoA (Mixture-of-Agents)」の概念と、それをDifyで具現化する方法について解説しました。
- 一人の天才より、有能なチームを: 単一の最強モデル探しに奔走する時代は終わりました。MoAは「複数の目」でチェックし合う構造を作ることで、出力の堅牢性、網羅性、創造性を次元の違うレベルに引き上げます。
- Difyならノーコードで並列オーケストレーション: コードで実装すると非同期処理の管理が煩雑になる複雑なMoAアーキテクチャも、Difyの「Parallelノード」を使えば、パズルを組み立てるように直感的に構築可能です。
- 適材適所でのROIの最大化: コストと処理時間が増加するため、「最高品質の回答が絶対に妥協できない重要タスク」に絞って局所的に導入する(インテリジェントなルーティングと組み合わせる)のが成功の鍵です。
AIエージェントの開発は、ひとつのプロンプトをこねくり回すフェーズから、特長の異なるAIモデルたちをどう配置し、どう連携させるかという「オーケストレーション(指揮・監督)」のフェーズへと進化しました。
あなたも今日からDifyを活用し、あなた専用の「頼れるAIチーム」による新しい働き方をぜひ体験してみてください!
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
👉 無料オンライン相談で、最適な導入プランを相談する
この記事を書いた人
関連記事
-
 AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価
AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価 -
Claude Code・Codexに機密情報を入れて大丈夫?情シスのためのセキュリティ設計ガイド
-
Claude Code GitHub Actionsでレビュー工数を削減した話 〜情シス・開発リーダーのためのチーム導入とセキュアCI設計〜
-
Microsoft Listsで脱・共有Excel。「壊れる・被る・履歴不明」を防ぐ移行手順を実演
-
AIの構造化データとは?図面・帳票を「AIが使える形」に変える全手法
-
【EDI 2024年問題】製造業のEDIツール完全ガイド|選定5観点とAI連携まで情シス向けに徹底解説
-
Hooksを活用してClaude Codeの処理制御に正解を出してみる
-
【セキュリティ】 プロンプトインジェクションの対策方法を徹底解説する







