
「自動デバッグ」をループ的に行う自律型エージェントをDify上に構築してみた

1. はじめに
「AIにコードを書かせたが、実行してみたらエラーで動かなかった」「結局人間が1行ずつデバッグする羽目になり、効率が上がらない……」といった悩みはありませんか?本記事を読めば、AIに「自己修正(Self-Correction)」という自衛能力を持たせ、人間が介在することなくエラーを自動で解消し、100%動作するコードを出力させる方法が分かります。
従来の単純なプロンプトエンジニアリングでは、AIに「一度だけ書かせる」アクセル(生成タスク)のみに留まるのが限界でした。しかし、複雑なシステム開発においては、AI自身が自分のミスを検知し、自律的にブレーキをかけて修正(検証・リフレクション)する仕組みが不可欠です。
本記事では、AIにおける自己修正の基本概念から、従来の「ワンショット生成」との決定的な違い、そしてDifyを使って実際に「エラーが出ると自分で直すAIエージェント」を構築する手順までを、分かりやすく解説します。
この記事で分かること
- 「ワンショット生成」の限界を突破する自己修正の凄さ:AIが自らエラーログを読み取り、人間と同じプロセスでデバッグを行う「自律型エージェント」の仕組みが理解できます。
- Difyによる「自動デバッグ・ループ」ワークフローの構築:Difyの「Python Sandbox(Codeノード)」と「ループ(Loop)ノード」を使い、エラーログを読み取って自律的に修正を行う実践的なワークフローの作り方が分かります。
2. 自己修正(Self-Correction)とリフレクションとは何か?
自己修正(Self-Correction)とは、AIが一度出した回答を自ら検証し、不備があれば修正案を練り直して出力する「思考のループ」のことです。
このプロセスにおいて中心的な役割を果たすのが、「リフレクション(Reflection:客観的考察)」というアプローチです。これは、AIが自分の生成物をあたかも「他人の成果物」であるかのように客観的にスキャンし、論理的な矛盾やエラーの痕跡を探し出す工程を指します。
2.1 なぜ「書かせるだけ(ワンショット)」では不十分なのか?
これまでのAI利用は、1回のプロンプトで1つの正解を得ようとする「ワンショット生成」が主流でした。しかし、コード生成の現場では以下のような現象が頻発します。
- 「動くはず」のハルシネーション: AIは自信満々にコードを出力しますが、実際には存在しないライブラリを呼び出していたり、型変換を忘れていたりします。
- 「文脈」の解釈ミス: 人間のあいまいな指示をAIが勝手に解釈し、要件とは微妙にズレたロジックを組んでしまいます。
人間も、一度もコンパイル(実行)せずに大規模なコードを完璧に書き上げるのは至難の業です。AIも同様に、「書いてみて、エラーを出し、それを直す」という試行錯誤の時間を与えることで、初めて実運用に耐えうる精度に到達します。この「失敗から学ぶ機会」をシステムとして組み込むのが自己修正の狙いです。
3. プロンプトエンジニアリングにおける、従来の「ワンショット生成」との違いと自己修正の圧倒的なメリット
これまでのコード生成は、いわば「一発勝負」のテストでした。自己修正の導入により、このプロセスは「合格するまで繰り返す再試行」へと進化します。
3.1 従来型「ワンショット生成」の限界
「AIなんだから一瞬で完璧なものを出すべきだ」という期待に対し、現実は以下のような課題に直面しています。
- 「人間による目視レビュー」がボトルネックに:
AIが生成したコードが正しいかどうか、結局エンジニアが自分のPCにコピペして実行し、エラーが出たらプロンプトを打ち直す……。これではAIによる省力化が半減してしまいます。 - エッジケースへの弱さ:
正常系(うまくいく場合)は書けても、異常系(入力が空、データ型が違うなど)への考慮が漏れやすく、本番環境でクラッシュする原因になります。
3.2 自己修正がもたらす3つの圧倒的な強み
| 強み | 従来の課題 | 自己修正(Self-Correction)の革新的メリット |
|---|---|---|
| 信頼性の劇的向上 | 生成されたコードがそのまま動く保証がなく、実行エラーの不安が常にあった。 | Dify内のSandboxで実際にコードを実行し、「成功した結果」のみをユーザーに返すため、出力の信頼性が格段に高まります。 |
| 高度なエラー対応能力 | エラーが出た際、どこをどう直せばいいか人間が指示しなければならなかった。 | Pythonのスタックトレース(エラー詳細ログ)をAIが自ら読み取り、「〇〇行目の型不一致が原因だ」と自立的に判断・修正して再出力します。 |
| コストと時間の最適化 | 人間が繰り返し修正指示を出す時間に比べ、明らかに早い。 | AI同士が高速にループを回すため、人間が介在するデバッグ工数をほぼゼロに削減でき、開発スピードが3〜5倍に向上します。 |
💡 具体的な業務シーンでの効果(劇的な工数削減)
たとえば、「複雑なデータ処理スクリプトの作成で、予期せぬ文字列が混ざって型エラー(TypeError)が発生した」というよくあるケース。
従来であれば、人間がいちいち「ローカルで実行 → エラー原因の特定 → AIへ修正指示 → 再生成」という手動のラリーを繰り返し、通常30分ほどかかっていたデバッグ時間が、Difyの自己修正ワークフローを通せば「AI自身の自動ループ3回(約15秒)」で完結します。
エンジニアはエラーの画面すら見ることなく、出来上がった「100%確実に動くコード」を受け取るだけで良くなるため、本来の創造的な開発業務に全力を注げるようになります。
3.3 既存のAIコーディングツール(Cursor・Copilot)との決定的な違い
「AIにコードを書かせるなら、CursorやGitHub Copilotなどを使えば十分では?」と思う方もいるかもしれません。しかし、これらは根本的な設計思想(アーキテクチャ)が異なります。
- Cursor / GitHub Copilot(支援型:Copilot):
エンジニアのローカルIDE(開発環境)に直接組み込まれ、人間と対話しながらコードを提案するツールです。最終的な実行とエラー確認、さらには「ここを直して」という文脈の指示は人間が手動で行う必要があります。 - Difyによる自己修正ワークフロー(自律実行型:Autopilot):
クラウド上の独立したエージェントとして稼働し、エラーの検知から原因分析、修正案の適用、そして再実行までを全自動でループします。人間のIDE環境に依存しないため、「Slackから指示を出して、裏側で勝手にスクリプト生成からテストまで終わらせて、完成品だけを返送させる」といった非同期の完全自動化システムへの組み込みにおいて圧倒的な力を発揮します。
つまり、日々のコーディングを「隣で手伝ってもらう」ならCursor、人間の手を完全に離れた自動化パイプラインを「任せる」ならDifyの自己修正、という明確な使い分けが理想的です。
4. 実践:Difyを使った「自動デバッグ・自己修正」ワークフローの構築
Difyのワークフロー機能を利用し、意図的に複数のAIタスクを連結させる「プロンプトチェーン(Prompt Chaining)」の実践として、条件を満たすまで繰り返すLoopノードと、コード実行を担うCodeノードを組み合わせます。これにより、単体のAIでは到達できないレベルの自律的な「自己修正エージェント」を構築できます。各ノードの設定ポイントを詳しく見ていきましょう。
4.1【活用】どのような「ユーザーの依頼」を想定するか?
graph TD
A[開始:ユーザーの依頼] --> B[Loop:ループ開始]
subgraph Loopノード内
B --> C[Agent:コード生成]
C --> D[Code:Python Sandboxで実行]
D --> E{If-Else:エラー有無?}
E -- 失敗(エラーあり) --> F[修正指示をフィードバックして再描画]
F --> C
end
E -- 成功(エラーなし) --> H[終了:結果を出力]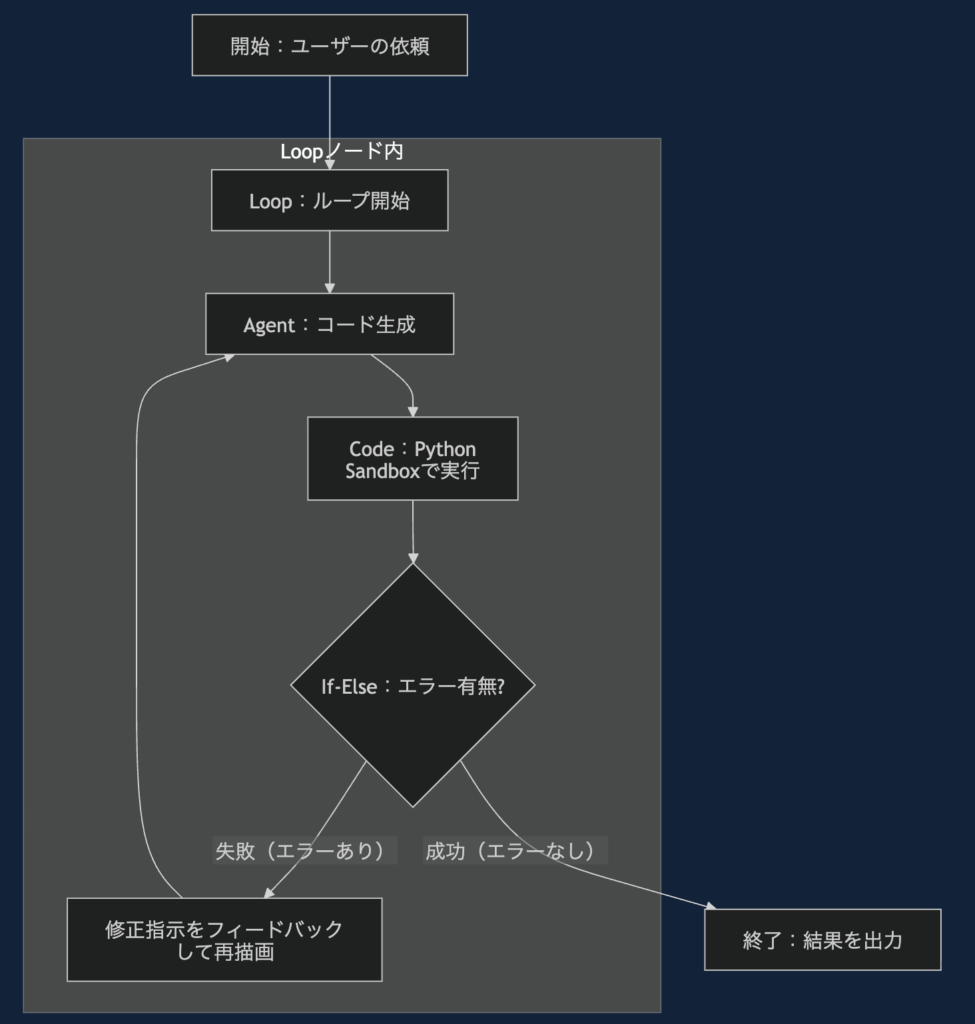
4.2【生成フェーズ】Agentノードの設定
まず、最初のドラフトを作成するAgentノードを配置します。
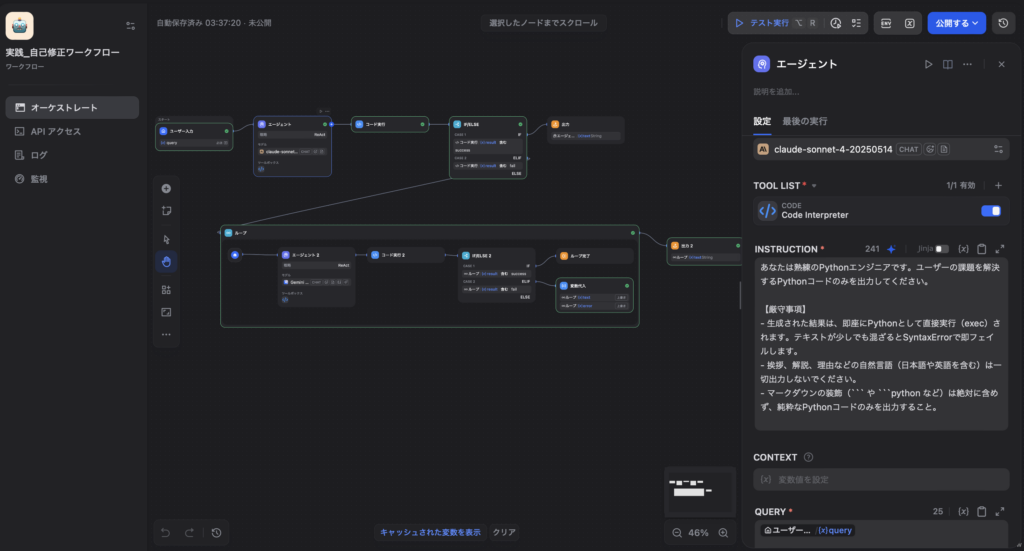
- モデル選定: コーディング能力の高いモデル(例:
claude-sonnet-4などの Claude 3.5 Sonnetクラス)を指定するのがおすすめです。 - 変数マッピング:
{{sys.query}}(ユーザーの元の依頼)を入力基点(QUERY)として設定します。 - ツール設定:
Code Interpreterツールを「有効」にしておくと、エージェントが高度な計算ロジックを自立的に組み立てやすくなります。 - プロンプト設計(INSTRUCTION): LLMが親切心で「はい、修正しました」と解説を入れるのを防ぐため、強い制約をかけます。 ““text あなたは熟練のPythonエンジニアです。ユーザーの課題を解決するPythonコードのみを出力してください。 【厳守事項】
- 生成された結果は、即座にPythonとして直接実行(exec)されます。テキストが少しでも混ざるとSyntaxErrorで即フェイルします。
- 挨拶、解説、理由などの自然言語(日本語や英語を含む)は一切出力しないでください。
- マークダウンの装飾(
やpython など)は絶対に含めず、純粋なPythonコードのみを出力すること。
““
💡 上級者向けTips ①:なぜLLMノードではなく「Agentノード」なのか?
Difyには「LLMノード」と「Agentノード」がありますが、自己修正にはAgentノードが最適です。
LLMノードは「指示に忠実」ですが、想定外のエラーに対する柔軟な推論が苦手です。一方、Agentノードは、エラーログという『新しい状況』を読み取って、次に何をすべきかを自律的に判断する「思考のゆとり」を持っています。だからこそ、人間が事前に「もしエラーAが起きたらこう直せ」と事細かにプロンプトで条件分岐を書いておかなくても、その場で遭遇した未知のエラー(ライブラリの仕様変更やコピペミスによる想定外のバグ)に対して柔軟に対応し、自力で解決策を導き出すことが可能になるのです。
4.3【検証フェーズ】Code実行ノード(Python Sandbox)
生成されたコード( エージェント / text )を引数として受け取り、Sandbox環境で実際に動かしてエラーがないかテストします。
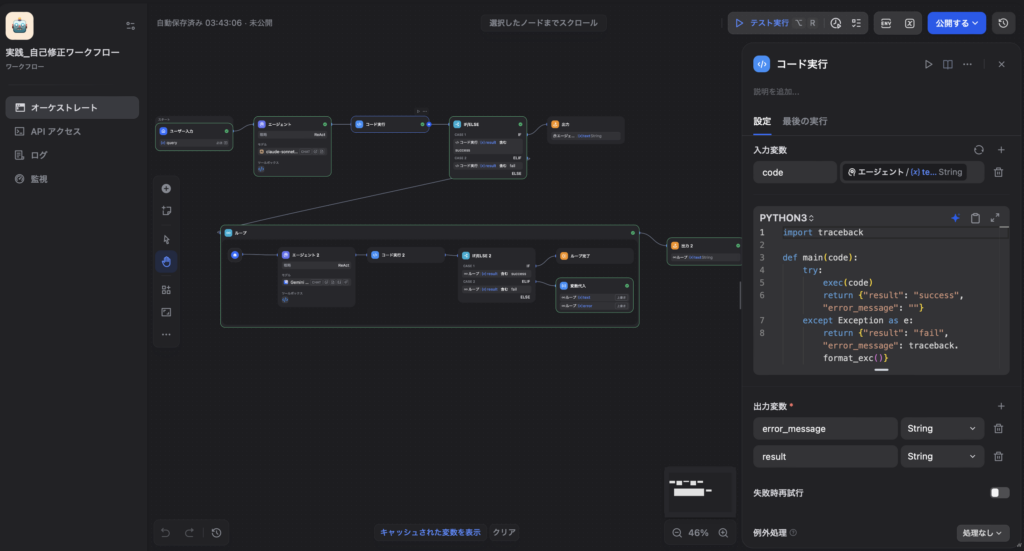
- 入力変数設定:
codeという変数を作り、値をエージェント / (x) textにマッピングします。 - 出力変数設定: 戻り値を受け取るために
error_messageとresultという2つのString変数を出力定義します。 - 例外処理設定: このノード自体がエラーで停止しないよう、設定パネル右下の「例外処理」は「処理なし」のままで構いません(コード内のtry-exceptで吸収するため)。
- ソースコード(try-exceptの活用):
Codeノード内で発生したエラーをキャッチし、詳細な内容をJSON形式で後続へ引き渡すように組みます。
python
import traceback
def main(code):
try:
exec(code)
return {"result": "success", "error_message": ""}
except Exception as e:
return {"result": "fail", "error_message": traceback.format_exc()}4.4【分岐フェーズ】If-Elseノードによる判定
Code実行ノードから返ってきた result(成功か失敗か)を判定し、後続のルートを決定します。
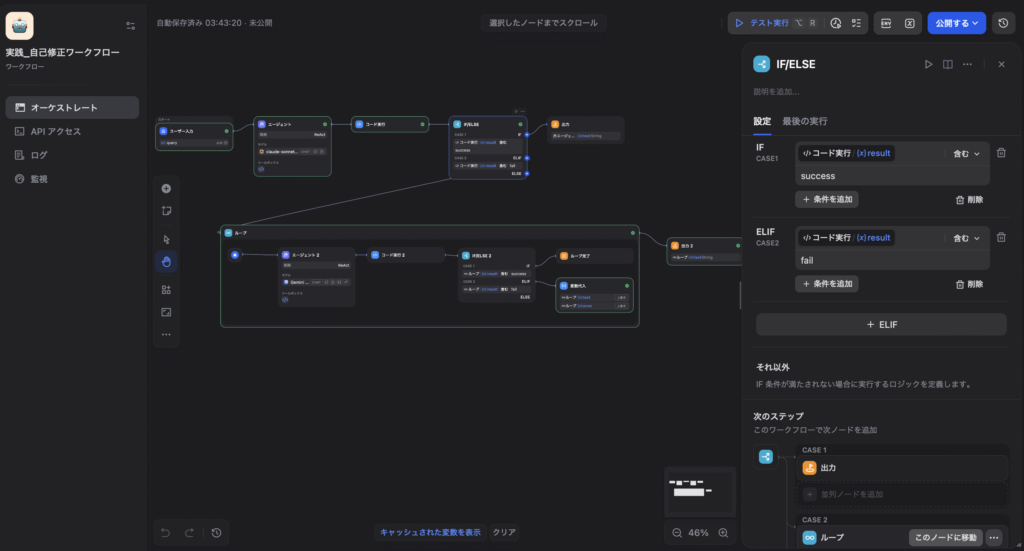
- CASE1(成功ルート): IF条件に
コード実行 / (x) resultがsuccessを「含む(contains)」と設定します。成功した場合は自己修正が不要なため、そのまま最終出力(Output)へ繋ぎます。 - CASE2(失敗ルート): ELIF条件に
コード実行 / (x) resultがfailを「含む(contains)」と設定します。ここでエラーメッセージを携えて、次の「自己修正ループ(Loop)」へと進みます。
4.5【修正フェーズ】LoopノードとAgent2による自動ブラッシュアップ
ここが自己修正の心臓部です。「エラーが起きている間だけ反復する」ために、IterationではなくLoopノードを使用します。
- ループの設定値:
- ループ変数: 次の反復に引き継ぐため、
text(直近の生成コード)、result(実行結果)、error(エラーログ)を変数として登録します。 - ループ終了条件: 設定せず、内部の分岐で解決するか、上限に達するまで回します。
- 最大ループ回数: 無限ループによるコスト暴走を防ぐため、
10程度に制限しておきます。
- ループ変数: 次の反復に引き継ぐため、
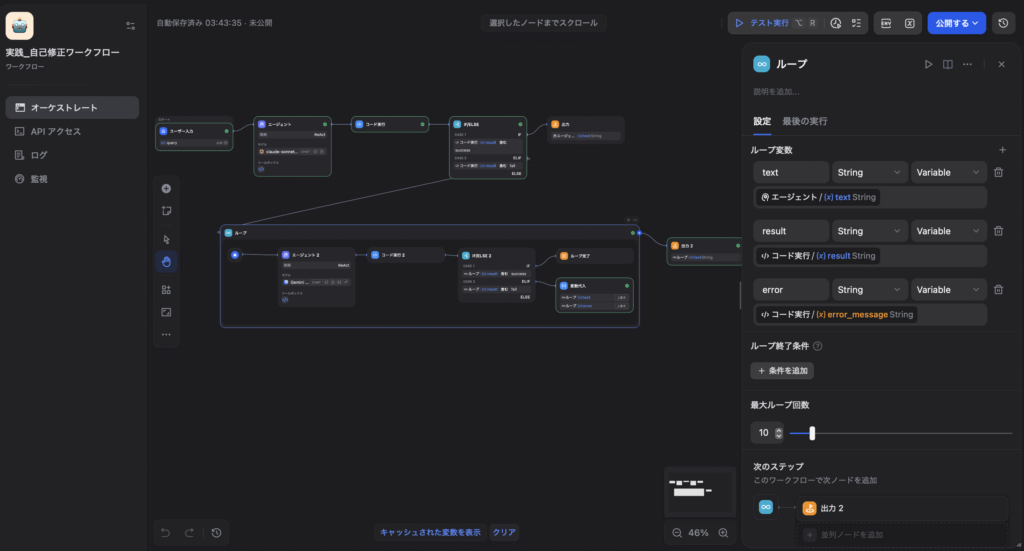
- 変数代入(Variable Assigner)ノードの配置(超重要):
自己修正ワークフローを組む際、最も多くの人がつまづく罠がここです。Loopノードの中でAgent 2が「新しく修正したコード」を書き、Codeノードが「新しいエラー結果」を出したとしても、そのままでは次のループに引き継がれません。
ループはそのままでは「記憶喪失」状態で回るため、常に1回目の最初の古いエラーログだけを読み込み続け、永遠に同じ修正を繰り返す「無限ループ」に陥ってしまいます。 これを防ぐため、分岐フェーズ(失敗ルート)の終端には必ず「変数代入ノード」を配置し、次回のループに渡すための変数を最新の結果で上書き(再代入)する必要があります。
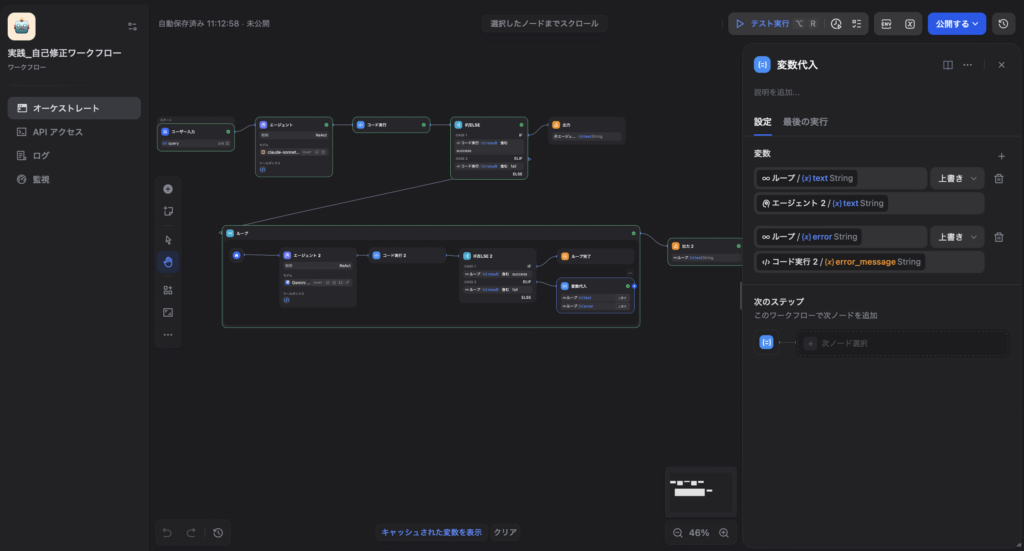
【具体的なマッピング設定(3点)】
1. ループ変数 `text`(コード) ← 上書き元: `Agent 2 / text`(新しく生成されたコード)
2. ループ変数 `result`(結果) ← 上書き元: `コード実行 2 / result`(新しい実行の成否)
3. ループ変数 `error`(エラーログ) ← 上書き元: `コード実行 2 / error_message`(新しいエラーの内容)
この「最新状態への上書き」を行うことで初めて、Agent 2が「さっき修正したけど、今度は別の行でエラーが出たぞ」と認識し、段階的にバグを解決していく自律的な推論ループが完成します。
- ループ内のエージェント(Agent 2)の設定:
- モデル選定: 何度も高速にデバッグを繰り返すため、推論速度とコストパフォーマンスに優れた
Gemini 2.5 Flashのような軽量かつ高性能なモデルが適しています。エージェンティック戦略: 「ReAct(Reasoning + Acting)」を推奨します。
- モデル選定: 何度も高速にデバッグを繰り返すため、推論速度とコストパフォーマンスに優れた
💡 【補足】ReAct戦略とは?
単純に「エラーを直せ実行しろ(Act)」とだけ指示するのではなく、「まずログから原因を推論・分析する(Reason)」という思考プロセスを強制的に挟む高度なプロンプトエンジニアリングの手法です。DifyのAgent設定でこのReActを有効にすることで、人間のように論理的にアプローチするため、複雑なエラー(型変換の見落としやロジック矛盾など)の解消率が飛躍的に高まります。
- プロンプト設計(INSTRUCTION): エラーログをそのまま渡しつつ、ここでも「テキスト混入禁止」を念押しします。
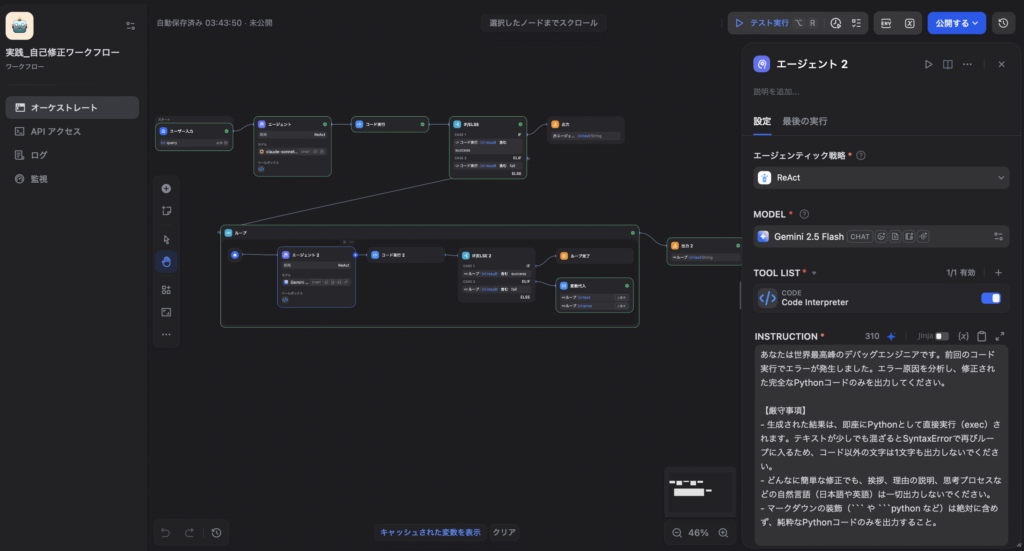
あなたは世界最高峰のデバッグエンジニアです。前回のコード実行でエラーが発生しました。エラー原因を分析し、修正された完全なPythonコードのみを出力してください。
【厳守事項】
- 生成された結果は、即座にPythonとして直接実行(exec)されます。テキストが少しでも混ざるとSyntaxErrorで再びループに入るため、コード以外の文字は1文字も出力しないでください。
- どんなに簡単な修正でも、挨拶、理由の説明、思考プロセスなどの自然言語(日本語や英語)は一切出力しないでください。
- マークダウンの装飾(``` や ```python など)は絶対に含めず、純粋なPythonコードのみを出力すること。💡 上級者向けTips ②:IterationではなくLoopを選ぶ理由
Iteration(イテレーション)は「配列の要素数だけ固定回数」繰り返す処理ですが、Loopは「特定の条件が満たされるまで(バグが消えるまで)」繰り返すため、自己修正タスクにはLoopが必須となります。
4.6 自己修正のBefore/After実例(完成コード)
自己修正ワークフローがどのように機能するのか、実際のテスト例で見てみましょう。たとえば、ユーザーがアプリに以下のような依頼を入力したとします。
依頼内容:
[10, "20", 30, "40"] という、数値と文字列が混ざったリストがあります。このリスト内のすべての要素を合計して、その結果を表示するPythonコードを書いてください
- Before(1回目:エラー発生):
エージェント1が最初のプロンプトで、文字列を考慮しない単純なコード(例:sum([10, "20", 30, "40"]))を生成して実行すると、計算に失敗します。
→ Sandboxエラーログ:TypeError: unsupported operand type(s) for +: 'int' and 'str'などが発生し、If-Elseノードで「fail」と判定されます。 - After(2回目:自己修正して出力された完成コード):
エラーログを受け取ったエージェント2(デバッグエンジニア)が原因を自律的に分析します。「文字列の “20” や “40” が混ざっているからintへのキャスト処理が必要だ」と気づき、以下のような確実に型判定を行うコードへと自力で書き直して再実行します。
data = [10, "20", 30, "40"]
total = 0
for item in data:
if isinstance(item, str):
total += int(item)
else:
total += item
print(total)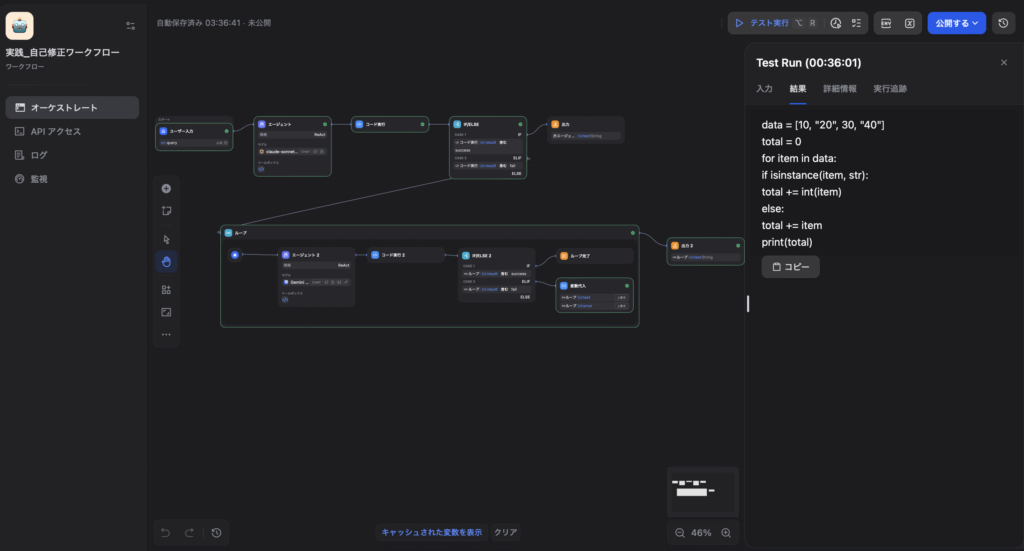
このように、人間がエラーを指摘して直させる手間がなく、AI自身がSandbox環境でテストとデバッグを繰り返し、「確実に実行できる洗練されたコード」だけを最終出力として返してくれるのが、このワークフローの最大の強みです。
4.7 さらに精度を上げる高度なテクニック(上級編)
自己修正ループの基本構成をマスターしたら、さらに実運用に耐えうる堅牢なシステムへ進化させるためのテクニックを組み込むことが可能です。
- RAG(ナレッジベース)との連動による「社内規約の徹底」
Agent 1(ドラフト生成)ノードに、自社の「コーディング規約」や「社内共通ライブラリのドキュメント」を持たせたナレッジ(RAG)を接続します。これにより、単に文法エラーを直すだけでなく、「この変数の命名規則は社内ルール(PEP 8の独自拡張など)に反しているから直す」といった、組織カルチャーに準拠したセルフチェック機能(リンターの上位互換)を持たせることができます。 - 構文チェック(Linter / Formatter)処理の追加
Code(Python Sandbox)ノードの手前、またはループ完了後の出力の直前に、BlackやFlake8のようなコードフォーマッターを実行する専用の判定処理を挟むプロンプトチェーンを構築します。これにより、論理エラーだけでなく「美しいコード(可読性)」を強制し、運用保守チームに見せても恥ずかしくない高品質なコードだけを最終出力させることが可能です。
5. 自己修正を利用する際のデメリットと注意点(Tips)
自己修正ワークフローは強力ですが、完璧だと過信するのは禁物です。現場で直面する課題と対策をまとめます。
5.1 避けて通れない「3つの制約」
- APIコストとレイテンシの増大: ループ1回ごとにコストと待ち時間(数秒〜)が積み重なります。
- ハルシネーションの連鎖: エラーを直そうとして、別の架空のライブラリを持ち出す等の「嘘の上塗り」が稀に発生します。
- 検証ロジック自体の不備: 正解のアサーションが間違っている場合、AIは正しいコードを破壊してしまいます。
5.2 自己修正を実運用に乗せるための「対策リスト」
- コストの暴走対策: ループの最大回数(Max Loop Count)を3回程度に制限する。
- 遅延(レイテンシ)対策: ユーザーを待たせない非同期処理として設計するか、処理ステータスを画面に表示する。
- 修正の質の低下対策: 指示の中に「まず原因を特定し、分析してからコードを修正せよ(ReAct手法)」と入れる。
- 環境との不適合対策: 事前に「使用可能な標準ライブラリ一覧」を明記し、Sandboxの枠外へ処理を出さないよう制約する。
- 誤った修正の防止策: 指定回数(例:3回連続)で失敗した場合はループを打ち切り、「人間が確認(HITL)」するプロセスへ移行する。
6. よくある質問(FAQ)
Q. Difyの無償版でも自己修正ループは作れますか?
A. 作成可能です。ただし、ループ内でLLM(Agent)を何度も反復して呼び出すため、メッセージ利用枠の消費が早くなる点にご注意ください。本格的な運用やテストを繰り返す場合は、ご自身のAPIキー(OpenAIやAnthropicなど)を設定して利用することを推奨します。
Q. エラーが永遠に直らず、無限ループに陥ってAPI代が爆発しませんか?
A. 大丈夫です。Loopノードの「最大ループ回数(Max Loop Count)」を設定(推奨:3〜10回程度)しておけば、その回数に達した時点で処理が強制終了されるため、無限ループによる暴走や過度なコスト課金は確実に防げます。
Q. 実践でAgent 2に「Gemini 1.5/2.5 Flash」を推奨していたのはなぜですか?
A. エラー修正のループは「何度も」「テキスト(ログ)を読んで」「素早く」処理する必要があるためです。Gemini Flash系のモデルは推論速度が非常に速く、APIコストも安価でありながらコンテキストウィンドウ(読み込める文章量)が広いため、長大なスタックトレースを読み込ませるデバッグ用途に最も適しています。
Q. Python以外の言語でも実行(Sandbox検証)は可能ですか?
A. 2026年のDify標準のCode実行ノード(Sandbox)環境は、主に Python3 と JavaScript に対応しています。本記事の例を応用すれば、Node.jsの手間のかかるスクリプトの自己修正も同様の手順で構築できます。
7. まとめ
本記事では、AIによる「ワンショット生成」の限界を打ち破る、Difyを活用した「自律型デバッグ・自己修正」ワークフローの構築手法を解説しました。
- 「一発出し」は運任せからの脱却: 複雑なシステムほど、AIが一度で完璧なコードを書くのは困難です。人間と同じように「エラーを出力から学び、自発的に直す」推論ループをシステムに組み込むことが、実運用において不可欠となります。
- Difyの圧倒的な柔軟性: 安全な実行環境である「Codeノード(Python Sandbox)」と、反復処理を制御する「Loopノード」の組み合わせにより、コードを一切書かずに「自己修正する自律型エージェント」のパイプラインを実現できるのがDify最大のメリットです。
- 高度なプロンプトエンジニアリングの真価: Agentノードへの「ReAct戦略」の適用や、「テキスト混入禁止」という強い制約(プロンプトチェーン)こそが、単なる自動反復を「知的な推論と修正のプロセス」へと押し上げ、複雑なエラーを確実に解消する要(かなめ)となります。
「AIがコードを書いてくれる時代」はすでに当たり前になりつつあります。次にエンジニアや開発担当者に求められるのは、「AIが書いた成果物をAI自身にテスト・修正させ、確実に動く状態まで責任を持たせる自動化パイプライン」を構築するシステム設計のスキルです。
今回作成した「自己修正ワークフロー」の考え方は、コーディングに限らず、データ抽出(Scraping)や文章の整合性チェック、複雑な社内業務フローの自動化など、あらゆるAI活用シーンに応用できる非常に強力な汎用概念です。
ぜひ本記事を参考に、手動でのイライラするデバッグ作業から解放され、Difyの自己修正エージェントが「100%動くコード」だけを献上してくれる、ストレスフリーで次世代的な開発リソースを手に入れてください!
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
👉 無料オンライン相談で、最適な導入プランを相談する
この記事を書いた人
関連記事
-
 AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価
AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価 -
Claude Code・Codexに機密情報を入れて大丈夫?情シスのためのセキュリティ設計ガイド
-
Claude Code GitHub Actionsでレビュー工数を削減した話 〜情シス・開発リーダーのためのチーム導入とセキュアCI設計〜
-
Microsoft Listsで脱・共有Excel。「壊れる・被る・履歴不明」を防ぐ移行手順を実演
-
AIの構造化データとは?図面・帳票を「AIが使える形」に変える全手法
-
【EDI 2024年問題】製造業のEDIツール完全ガイド|選定5観点とAI連携まで情シス向けに徹底解説
-
Hooksを活用してClaude Codeの処理制御に正解を出してみる
-
【セキュリティ】 プロンプトインジェクションの対策方法を徹底解説する







