
DifyのRAG精度を飛躍させる Contextual Retrieval構築マニュアル

はじめに
RAGの検索精度が悪い原因、実は「チャンク分割」にあるかもしれません。本記事を読めば、その根本原因を理解した上で、Difyですぐに使えるプロンプトとコードの実装手順が分かります。
ドキュメントを小さなチャンク(断片)に分割してベクトル化するのがRAGの基本ですが、分割した瞬間に「これは何の情報なのか」という文脈が消えてしまうのです。「売上が3%増加した」——これだけでは、どの会社の、いつの話なのか分かりません。
この課題を解決するのが、Anthropicが提唱するContextual Retrievalです。各チャンクにLLMで「文脈情報」を自動付加することで、検索エラーを最大67%削減できます。Difyでの実装方法に加え、前回紹介したHyDEとの使い分け・併用の判断基準も解説します。
1. 従来RAGの課題:チャンク分割で失われる「文脈」
1.1 なぜチャンク分割が問題になるのか
RAGでは、ドキュメントを検索しやすいサイズのチャンク(断片)に分割します。
チャンクとは?
長いドキュメントを検索・処理しやすいように区切った「断片」のことです。たとえば、100ページの就業規則を「条文ごと」や「500文字ごと」に分割したものがチャンクです。
しかし、チャンクに分割すると元のドキュメント内での位置づけや前後関係が失われます。
1.2 具体例:文脈が消えるとどうなるか
以下の就業規則を例に考えてみましょう。
元のドキュメント(就業規則 第12条):
従業員の年次有給休暇は、労働基準法に基づき以下のとおり付与する。勤続6か月で10日、1年6か月で11日、2年6か月で12日…
チャンクに分割した後:
勤続6か月で10日、1年6か月で11日、2年6か月で12日…
チャンクだけを見ると、何の「10日」なのか分かりません。有給休暇の日数なのか、研修期間なのか、チャンクからは判断できません。検索時に「有給休暇」というキーワードでヒットしにくくなるのです。
2. Contextual Retrievalとは?
Contextual Retrievalとは、ドキュメントを分割(チャンク化)する際に失われる文脈を、LLMを使って事前に補完し、RAGの検索精度を飛躍的に高める手法です。
2.1 Anthropicのアプローチ
Contextual Retrievalは、Anthropicが2024年9月に発表した手法です。
アイデアはシンプル——チャンクを保存する前に、LLMで「このチャンクは何の情報か」という文脈を自動生成し、チャンクの先頭に追加する。
従来RAG: ドキュメント → チャンク分割 → そのままベクトル化 → 保存
Contextual Retrieval: ドキュメント → チャンク分割 → LLMで文脈を生成 → 文脈をチャンクに追加 → ベクトル化 → 保存2.2 文脈付加の実例
元のチャンク:
勤続6か月で10日、1年6か月で11日、2年6か月で12日、3年6か月で14日…
文脈付きチャンク(Contextual Retrieval適用後):
[就業規則 第12条(年次有給休暇)からの抜粋。従業員に付与される年次有給休暇の日数を、勤続年数ごとに定めた条文。] 勤続6か月で10日、1年6か月で11日、2年6か月で12日、3年6か月で14日…
文脈が追加されたことで、「有給休暇」「就業規則」「勤続年数」といったキーワードでも検索にヒットするようになります。
2.3 なぜこれで精度が上がるのか
Contextual Retrievalが効果的な理由は2つあります。
- 意味的な検索(ベクトル検索)が改善: 文脈情報が加わることで、チャンクのベクトルがより正確な位置に配置される
- キーワード検索(BM25)も改善: 文脈に含まれるキーワードにより、キーワード一致でもヒットしやすくなる
Anthropicの検証では、この2つを組み合わせることでエラーを最大67%削減しています。
2.4 Contextual Retrievalの強み
| 強み | 説明 |
|---|---|
| 事前処理型 | ドキュメント登録時に1回だけLLMを呼び出す。検索時の遅延がない |
| 低コスト | 文脈生成にはClaude Haikuなどの軽量モデルで十分 |
| 両方の検索に効く | ベクトル検索とキーワード検索の両方の精度が向上する |
3. Difyを使ったContextual Retrievalの実装手順とプロンプト
実装の考え方
Difyのナレッジベースに登録する前処理として、ドキュメントの各チャンクにLLMで文脈を付加するワークフローを構築します。
ワークフロー全体像
[開始:ドキュメントのテキスト入力]
↓
[コードノード:チャンクに分割]
↓
[イテレーションノード:各チャンクに対して繰り返し]
├── [LLMノード:文脈情報を生成]
└── [テンプレートノード:文脈 + チャンクを結合]
↓
[終了:文脈付きチャンク一覧を出力]Step 1:新規ワークフローの作成
- Difyダッシュボードで「スタジオ」→「アプリを作成」をクリック
- 「ワークフロー」タイプを選択
- アプリ名を設定(例:「Contextual Retrieval 前処理」)
- 「作成」をクリック
Step 2:開始ノードの設定
以下の入力変数を追加します。
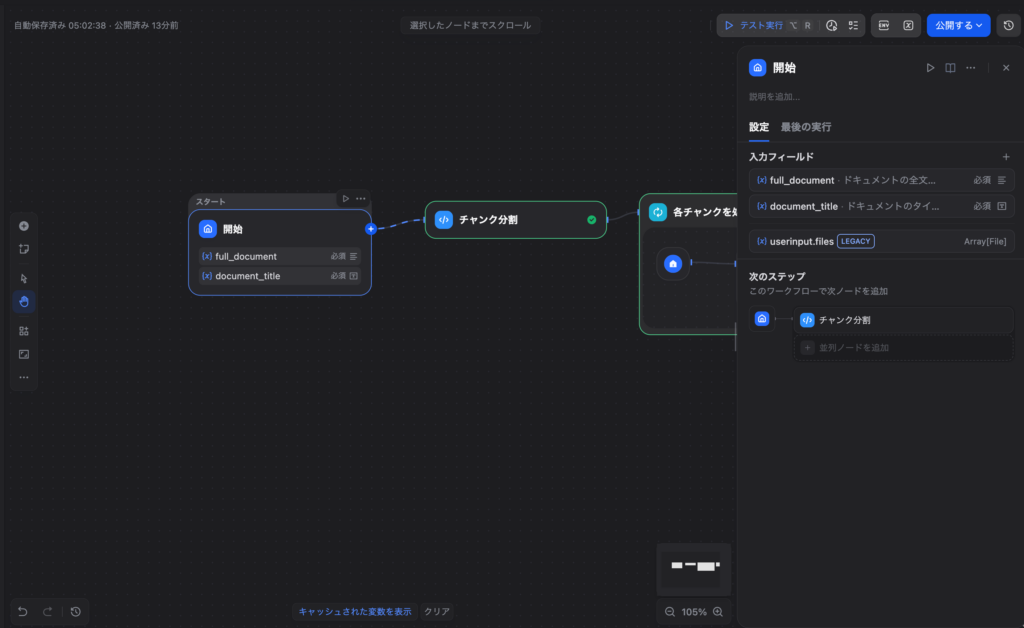
full_document(段落): ドキュメントの全文テキストdocument_title(テキスト): ドキュメントのタイトル(例:「就業規則」)
Step 3:コードノード(チャンク分割)
Pythonコードでドキュメントをチャンクに分割します。
def main(full_document: str) -> dict:
import re
# 改行+全角スペース、または空行で段落分割
chunks = [chunk.strip() for chunk in re.split(r'\n |\n\n', full_document) if chunk.strip()]
return {"chunks": chunks}入力変数:
full_document: 開始ノードのfull_document
出力変数:
chunks(Array[String]): 分割されたチャンクのリスト
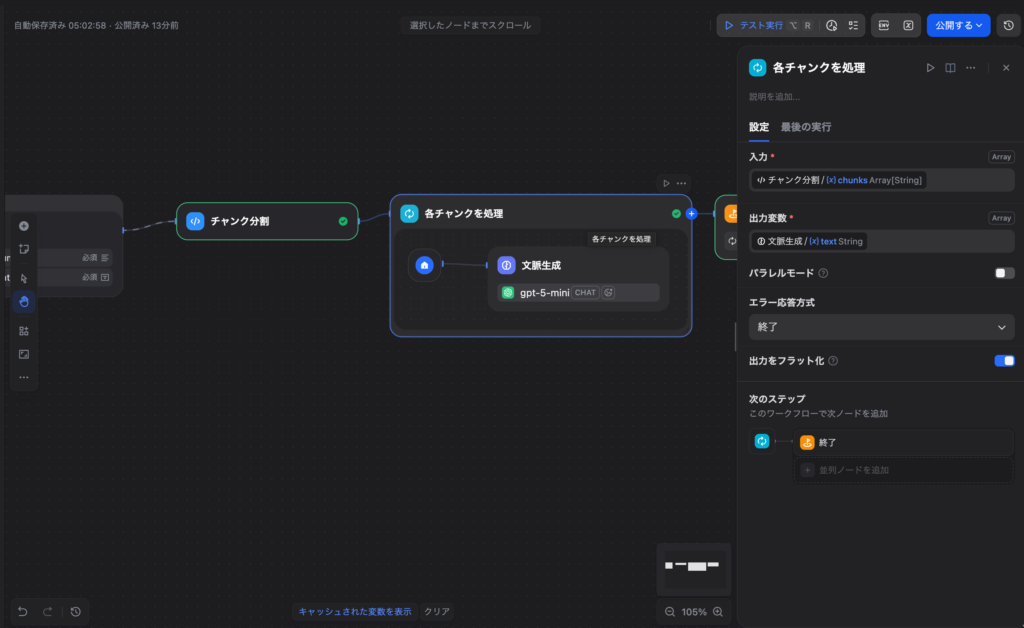
Step 4:イテレーションノード(各チャンクを処理)
イテレーションノードを追加し、以下のように設定します。
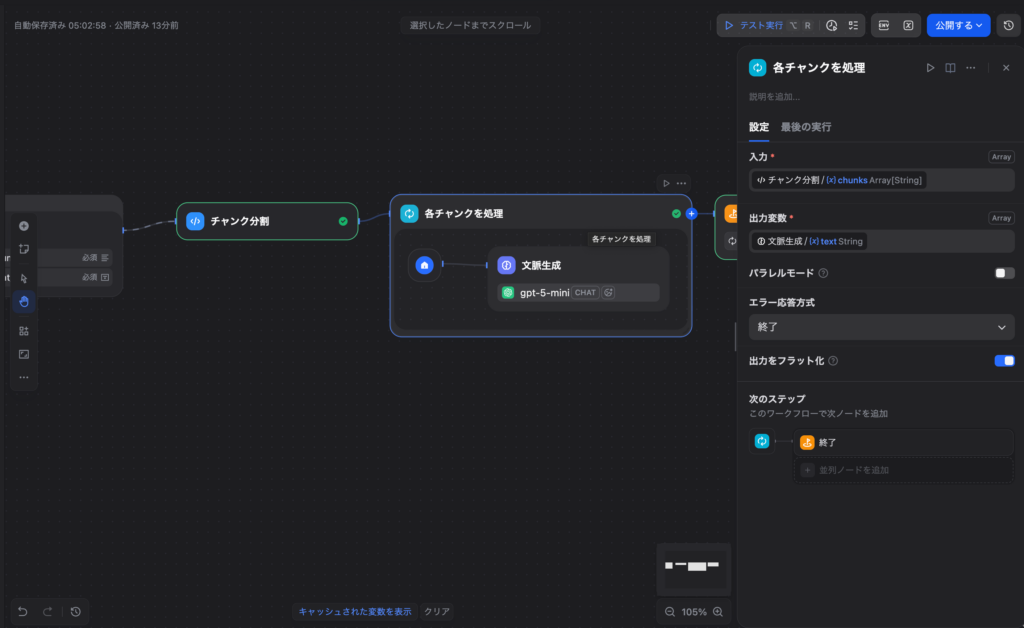
- 入力変数: コードノードの出力
chunks(Array[String])を選択
イテレーション内では、配列の各要素が {{#item#}} として参照できます。この中に以下の2つのノードを追加します。
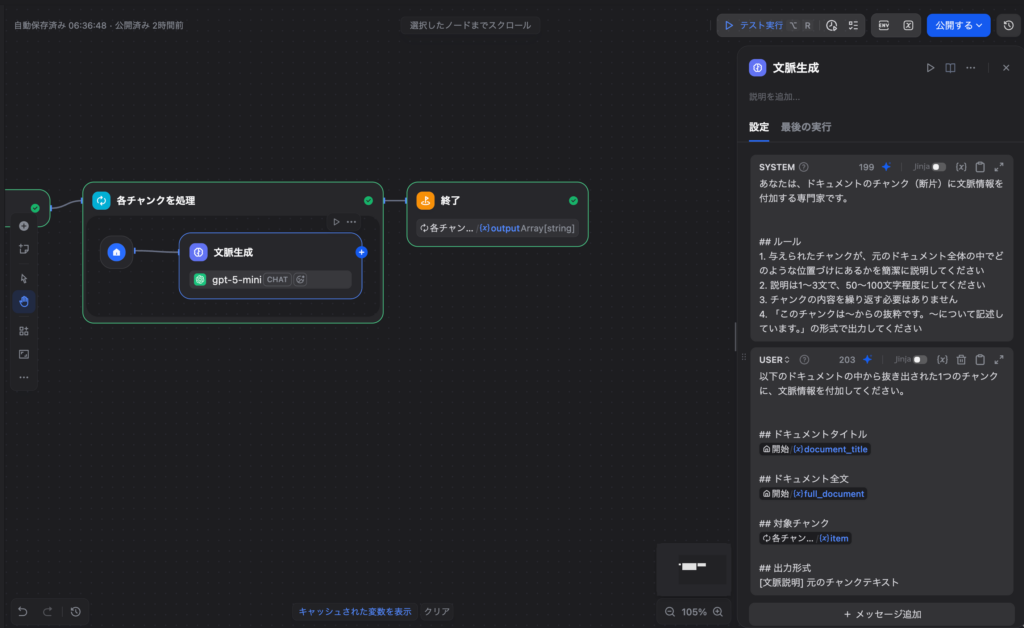
LLMノード(文脈生成)
LLMノードの入力変数を以下のように設定します。
| 変数名 | 参照元 | 説明 |
|---|---|---|
{{#start.document_title#}} | 開始ノードの document_title | ドキュメントのタイトル |
{{#start.full_document#}} | 開始ノードの full_document | ドキュメントの全文 |
{{#item#}} | イテレーションの現在の要素 | 処理中のチャンク(自動で設定済み) |
システムプロンプト:
あなたは、ドキュメントのチャンク(断片)に文脈情報を付加する専門家です。
## ルール
1. 与えられたチャンクが、元のドキュメント全体の中でどのような位置づけにあるかを簡潔に説明してください
2. 説明は1〜3文で、50〜100文字程度にしてください
3. 出力は必ず [文脈説明] 元のチャンクテキスト の形式にしてください
4. 元のチャンクテキストはそのまま変更せず含めてくださいユーザープロンプト:
以下のドキュメントの中から抜き出された1つのチャンクに、文脈情報を付加してください。
## ドキュメントタイトル
{{#start.document_title#}}
## ドキュメント全文
{{#start.full_document#}}
## 対象チャンク
{{#item#}}
## 出力形式
[文脈説明] 元のチャンクテキスト💬 実践Tips: 文脈生成のモデルにはGPT-4o-miniやClaude Haikuなど軽量モデルで十分です。チャンクの数だけLLMを呼び出すので、コスト面では軽量モデルの方が圧倒的
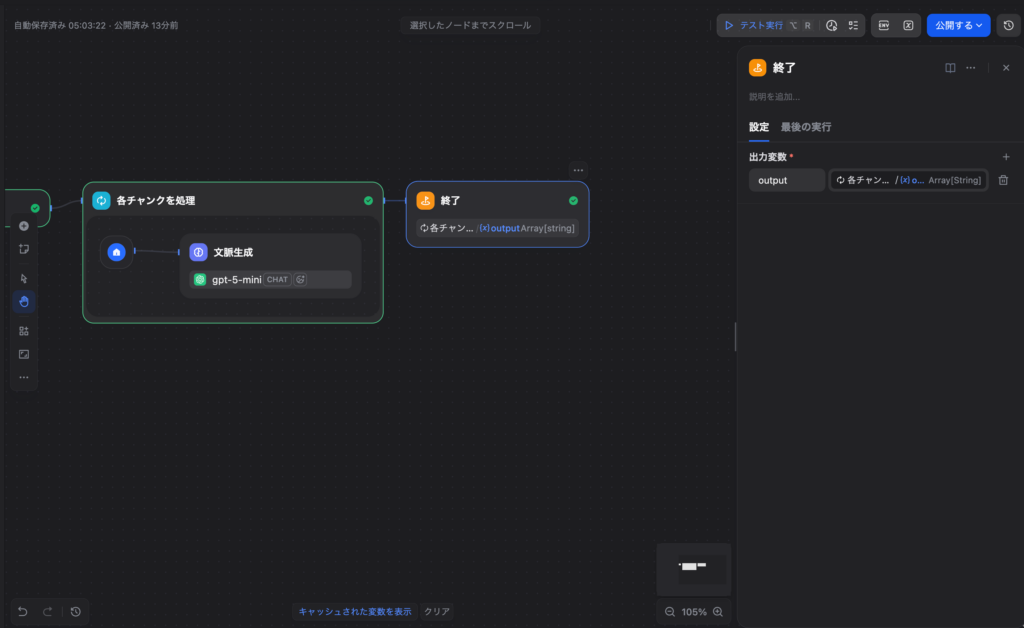
Step 5:終了ノード
イテレーションの出力(文脈付きチャンクの配列)を出力します。
文脈付きチャンクのナレッジ登録
ワークフローで生成された文脈付きチャンクを、Difyのナレッジベースに登録します。すでに文脈が含まれているため、ナレッジベースの検索精度が自然と向上します。
💡 ポイント: このワークフローはドキュメント登録時の前処理として1回だけ実行します。一度文脈付きチャンクを作成してナレッジベースに登録すれば、以降の検索では通常のRAGと同じ速度で動作します。
【上級者向け】Prompt Cachingでコストをさらに削減
Contextual Retrievalでは、各チャンクの文脈を生成するためにLLMをチャンクの数だけ呼び出す必要があります。このとき、プロンプトに含まれる「ドキュメント全文」の部分は毎回まったく同じです。
[システムプロンプト(毎回同じ)]
[ドキュメント全文(毎回同じ)] ← ここがコストの大部分
[対象チャンク(毎回変わる)] ← ここだけ違うPrompt Cachingという仕組みを使えば、この「毎回同じ」の部分をキャッシュして入力トークンのコストを最大90%削減できます。
| 項目 | キャッシュなし | キャッシュあり |
|---|---|---|
| 1回目 | 通常料金 | 通常料金(キャッシュ作成) |
| 2回目以降 | 通常料金 | キャッシュ読み込み料金(大幅割引) |
Anthropicの Claude APIでは cache_control パラメータを使うことでPrompt Cachingを利用でき、Contextual Retrievalとの相性が非常に良いです。100チャンクのドキュメントなら、2回目以降の99回分のドキュメント全文の読み込みコストが大幅に下がります。
💬 実践Tips: DifyのLLMノードから直接Prompt Cachingを利用するにはAPI設定の工夫が必要ですが、Anthropic APIを直接呼び出すHTTPリクエストノードを使えば
cache_controlを指定できます。大量のドキュメントを処理する場合は検討してみてください。
4. テスト結果:文脈付加の効果を確認
実際にDifyで構築したワークフローを使い、テーマ:「社会経済システム論」のレポートを処理してみました。
4.1 チャンク分割の結果
約3,000文字のドキュメントが6つのチャンクに分割されました。
| 文脈なし(従来) | 文脈あり(Contextual Retrieval) |
|---|---|
| 現代の資本主義が直面する… | [文書冒頭の導入部分。中間層の定義と没落問題の導入] 現代の… |
| その要因にはさまざまなものが… | [中間層の没落要因の節。教育格差や労働市場の構造変化] その要因には… |
| そしてこの中間層の没落は… | [影響論の節。中間層没落の経済的・政治的影響] そしてこの中間層の… |
| 次にこれらのことを踏まえて… | [資本主義の転換と中間層再建の章。教育改革や累進課税] 次にこれらの… |
| このように資本主義の課題の… | [格差や環境問題と制度の見直し] このように資本主義の… |
| 最後に資本主義の未来について… | [結論部。環境適応や労働再編(再教育・ベーシックインカム)] 最後に… |
4.2 従来のRAGとContextual Retrievalの検索性比較
たとえば「非正規雇用の問題について教えて」と検索した場合を考えます。
従来のチャンク(文脈なし):
- チャンク2に「非正規雇用」というキーワードが含まれるためヒットする可能性がある
- ただし、チャンク単体では「これは中間層没落の要因分析である」という位置づけが不明
文脈付きチャンク(Contextual Retrieval適用済み):
- チャンク2の文脈に「教育格差や労働市場の構造変化」と明記されているため、意味的にもヒットしやすい
- さらに「中間層の没落要因」という文脈が付いているため、回答生成時にLLMがより正確な文脈で回答できる
4.3 処理コスト
| 項目 | 値 |
|---|---|
| チャンク数 | 6 |
| LLM呼び出し回数 | 6回 |
| 使用モデル | GPT-4o-mini |
| 処理時間 | 約15秒 |
💬 実践Tips: 今回は6チャンクなのでコストはほぼ無視できますが、100ページを超えるドキュメントでは数百チャンクになることもあります。その場合は前述のPrompt Cachingの活用が効果的です。
5. HyDEとの比較:どちらを使うべきか
前回のブログで紹介したHyDEと、今回のContextual Retrieval——どちらもRAGの検索精度を改善する手法ですが、アプローチが異なります。
前回の記事はこちらから↓

5.1 アプローチの違い
HyDE: 検索時にクエリ側を改善(仮説回答を生成)
Contextual Retrieval: 登録時にドキュメント側を改善(文脈を付加)5.2 比較表
| 比較項目 | Contextual Retrieval | HyDE |
|---|---|---|
| 改善対象 | ドキュメント(チャンク)側 | クエリ(質問)側 |
| 処理タイミング | ドキュメント登録時(1回) | 検索のたびに毎回 |
| 検索時の遅延 | なし | LLM呼び出し分の遅延あり |
| 登録時のコスト | チャンク数 × LLM呼び出し | なし |
| 検索時のコスト | なし | 毎回LLM呼び出し |
| 得意な場面 | 文脈が失われやすい構造化文書 | 曖昧・短い質問 |
5.3 Contextual Retrievalの注意点・デメリット
| 注意点 | 説明 |
|---|---|
| 初期登録時のコスト | チャンクの数だけLLMを呼び出すため、大量ドキュメントではAPIコストと処理時間がかかる |
| 更新時に再処理が必要 | ドキュメントの内容が変わった場合、文脈の再生成と再登録が必要になる |
| 文脈の品質がLLMに依存 | 生成される文脈の質はモデルの性能に左右される。不適切な文脈が付くと逆効果になる可能性もある |
💬 実践Tips: コスト面は前述のPrompt Cachingで大幅に軽減できます。また、更新頻度が高いドキュメントには、登録時の前処理が不要なHyDEの方が適しています。
5.4 使い分けガイド
| 状況 | おすすめ |
|---|---|
| ドキュメントの構造が明確で、チャンクの文脈が失われやすい | Contextual Retrieval |
| ユーザーの質問が曖昧・短いことが多い | HyDE |
| 検索のレスポンス速度が重要 | Contextual Retrieval(検索時の遅延なし) |
| ドキュメントが頻繁に更新される | HyDE(登録時の前処理が不要) |
| 最高精度を追求したい | 両方を組み合わせる |
💬 実践Tips: Contextual RetrievalとHyDEは併用が可能です。ドキュメント側に文脈を付加しつつ、検索時にHyDEで仮説回答を生成する——両方のアプローチを組み合わせることで、さらに検索精度の向上が期待できます。
6. まとめ
- 課題: チャンク分割時に「何の情報か」という文脈が失われ、検索精度が低下する
- 解決策: Contextual Retrieval=LLMで各チャンクに文脈情報を自動付加してから保存する
- Difyでの実装: ワークフローでチャンク分割→イテレーションで文脈生成→文脈付きチャンクをナレッジ登録
- HyDEとの使い分け: Contextual Retrievalは登録時の前処理、HyDEは検索時のクエリ改善。併用も可能
Contextual Retrievalはドキュメント登録時に1回処理するだけで、その後の検索精度が恒久的に改善される手法です。特に就業規則のような構造化文書では効果が顕著なので、ぜひDifyで試してみてください。
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
👉 無料オンライン相談で、最適な導入プランを相談する
参考文献
Anthropic. “Introducing Contextual Retrieval.” (2024年9月) https://www.anthropic.com/news/contextual-retrieval
この記事を書いた人
関連記事
-
 AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価
AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価 -
Claude Code・Codexに機密情報を入れて大丈夫?情シスのためのセキュリティ設計ガイド
-
Claude Code GitHub Actionsでレビュー工数を削減した話 〜情シス・開発リーダーのためのチーム導入とセキュアCI設計〜
-
Microsoft Listsで脱・共有Excel。「壊れる・被る・履歴不明」を防ぐ移行手順を実演
-
AIの構造化データとは?図面・帳票を「AIが使える形」に変える全手法
-
【EDI 2024年問題】製造業のEDIツール完全ガイド|選定5観点とAI連携まで情シス向けに徹底解説
-
Hooksを活用してClaude Codeの処理制御に正解を出してみる
-
【セキュリティ】 プロンプトインジェクションの対策方法を徹底解説する







