
RAG検索精度の革命|HyDEの理論からDify実装・検証まで完全解説

はじめに
「質問をそのまま検索しても、的外れな結果ばかり…」——RAGシステムでこんな経験はありませんか?
ユーザーの質問文と、回答が記載されたドキュメントは、文章のスタイルがまったく異なります。質問は短く曖昧なのに対し、ドキュメントは長く詳細、この「ギャップ」こそが検索精度を下げる大きな原因です。
そこで注目されているのがHyDE(Hypothetical Document Embeddings)という手法です。質問から「仮の回答」を先に生成し、その回答文で検索を行います。質問→文書ではなく、回答→文書の類似度で検索することで、的確な情報にたどり着けます。
本記事では、HyDEの仕組みを解説し、Difyのワークフローで実装する具体的な方法をご紹介します。
1. 従来RAGの課題:「質問」と「回答」のギャップ
1.1 なぜ質問文での検索は精度が出にくいのか
従来のRAGでは、ユーザーの質問文をベクトル化(エンベディング)して類似ドキュメントを検索します。
ベクトル化(エンベディング)とは?
文章の「意味」を数百個の数値の並び(ベクトル)に変換する処理のことです。たとえば「犬」と「猫」は見た目は違いますが、意味が近いので似た数値の並びに変換されます。この仕組みにより、キーワードが一致しなくても意味が近い文書を検索できるのが、RAGの基本です。
しかし、質問文と回答文は文章のスタイルが根本的に異なるため、意味が近くてもベクトルが離れてしまうことがあります。
| 質問文 | ドキュメント(回答) | |
|---|---|---|
| 長さ | 短い(1〜2文) | 長い(段落〜ページ) |
| スタイル | 疑問形・曖昧 | 説明文・断定的 |
| 情報量 | 少ない | 豊富 |
| 例 | 「避難所の選び方は?」 | 「避難所を選ぶ際は、標高、浸水想定の有無、避難経路の安全性を確認し…」 |
1.2 具体例で見るギャップ
例えば、以下の質問を考えてみましょう。
「台風のときに気をつけることは?」
この質問文をベクトル化すると、「台風」「気をつける」という単語の近くにマッピングされますが、実際に知りたい回答(避難手順、防災グッズ、気象情報の確認方法など)とは異なるベクトル空間の位置に置かれてしまいます。
結果として、「台風」に関する一般的な文章は引っかかっても、具体的な対策が書かれた文書を見逃す可能性があります。
2. HyDEとは?仮説文書で検索精度を上げる仕組み
2.1 HyDEの基本アイデア
HyDE(Hypothetical Document Embeddings) は、Precise Zero-Shot Dense Retrieval without Relevance Labelsに提案された手法です。
簡単に説明すると検索する前に、LLMに「仮の回答」を生成させる。
従来RAG: 質問 → ベクトル化 → 類似文書を検索 → LLM回答
HyDE: 質問 → LLMが仮説回答を生成 → 仮説回答をベクトル化 → 類似文書を検索 → LLM回答2.2 なぜこれで精度が上がるのか
HyDEの効果は「回答同士の類似度は、質問と回答の類似度より高い」という性質に基づいています。
LLMが生成した仮説回答は、実際のドキュメントと同じ「回答文」のスタイルで書かれています。たとえ仮説回答に事実誤認が含まれていても、文体・キーワード・構造が実際の回答文書に似ているため、ベクトル空間上で正解のドキュメントの近くに配置されます。
つまり、「質問→文書」の検索を「回答→文書」の検索に変換することで、検索精度が大幅に向上するのです。
2.3 HyDEの3つの強み
| 強み | 説明 |
|---|---|
| ゼロショット対応 | AIの追加学習や教師データが不要。新規ドメインでも即座に使える |
| 多言語対応 | 日本語・英語・韓国語など、多言語で効果が確認されている |
| 既存RAGとの組み合わせ | 既存のベクトル検索パイプラインに1ステップ追加するだけで導入可能 |
3. DifyでHyDEを実装する
ワークフロー全体像
DifyのワークフローでHyDEを実装する際の構成は以下の通りです。
[開始:ユーザークエリ]
↓
[LLMノード①:仮説回答の生成]
↓
[ナレッジ検索ノード:仮説回答で検索]
↓
[LLMノード②:検索結果をもとに最終回答を生成]
↓
[終了]Step 1:新規ワークフローの作成
- Difyダッシュボードで「スタジオ」→「アプリを作成」をクリック
- 「チャットフロー」タイプを選択
- アプリ名を設定(例:「HyDE検索チャットボット」)
- 「作成」をクリック
Step 2:開始ノードの設定
チャットフローの場合、開始ノードにはデフォルトで sys.query(ユーザーの入力)が含まれています。追加の入力変数は不要です。
Step 3:LLMノード①(仮説回答の生成)
LLMノードを追加し、以下のプロンプトを設定します。
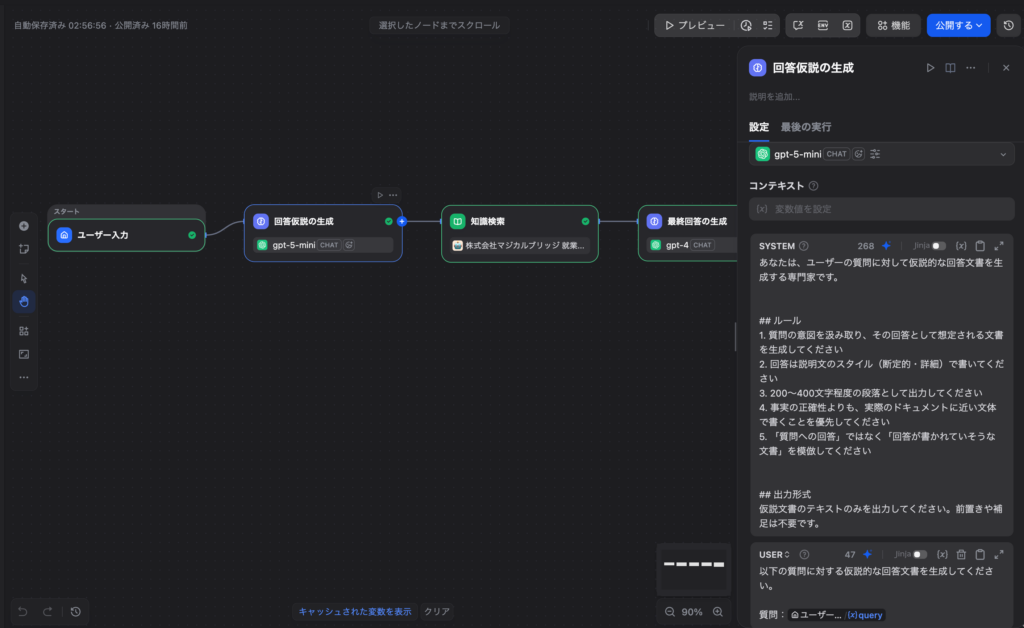
システムプロンプト:
あなたは、ユーザーの質問に対して仮説的な回答文書を生成する専門家です。
## ルール
1. 質問の意図を汲み取り、その回答として想定される文書を生成してください
2. 回答は説明文のスタイル(断定的・詳細)で書いてください
3. 200〜400文字程度の段落として出力してください
4. 事実の正確性よりも、実際のドキュメントに近い文体で書くことを優先してください
5. 「質問への回答」ではなく「回答が書かれていそうな文書」を模倣してください
## 出力形式
仮説文書のテキストのみを出力してください。前置きや補足は不要です。ユーザープロンプト:
以下の質問に対する仮説的な回答文書を生成してください。
質問:{{#sys.query#}}💡 ポイント: ここでの目的は「正確な回答」ではなく「検索に適した文書」を生成することです。LLMの知識に誤りがあっても問題ありません——エンベディング化した際に正しいドキュメントの近くに配置されることが重要です。
Step 4:ナレッジ検索ノード
ナレッジ検索ノードを追加し、以下のように設定します。
- クエリ変数: LLMノード①の
text(仮説回答のテキスト)を選択 - ナレッジベース: 検索対象のナレッジベースを選択
- 検索設定: ベクトル検索を推奨(HyDEの効果が最も発揮される)
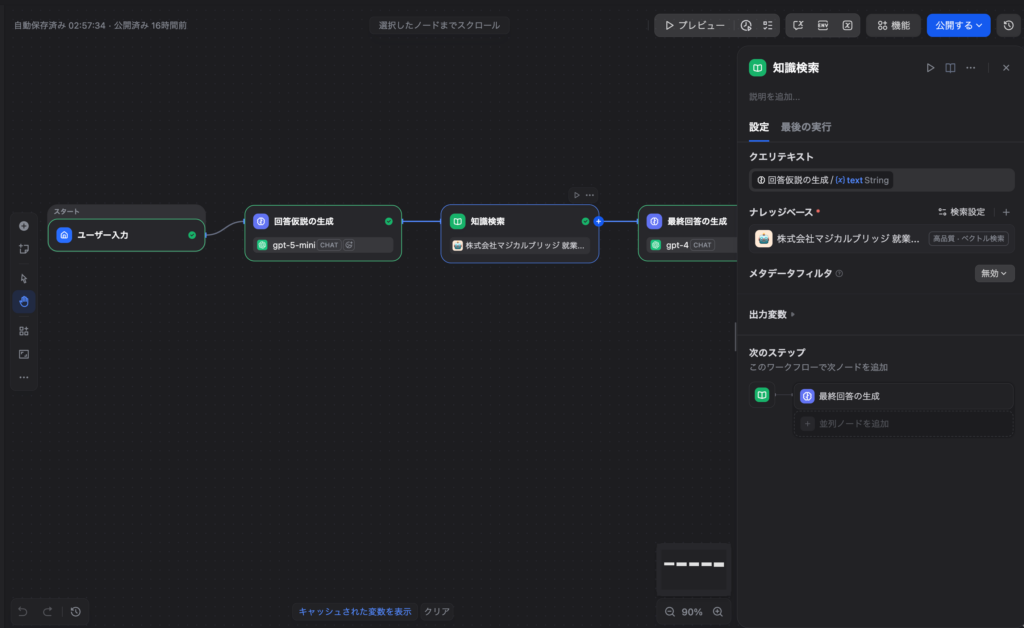
⚠️ 重要: クエリ変数に
sys.query(元の質問文)ではなく、LLMノード①の出力を設定するのがHyDEの核心です。ここを間違えると従来RAGと同じになります。
Step 5:LLMノード②(最終回答の生成)
最後のLLMノードを追加し、検索結果をもとに回答を生成します。
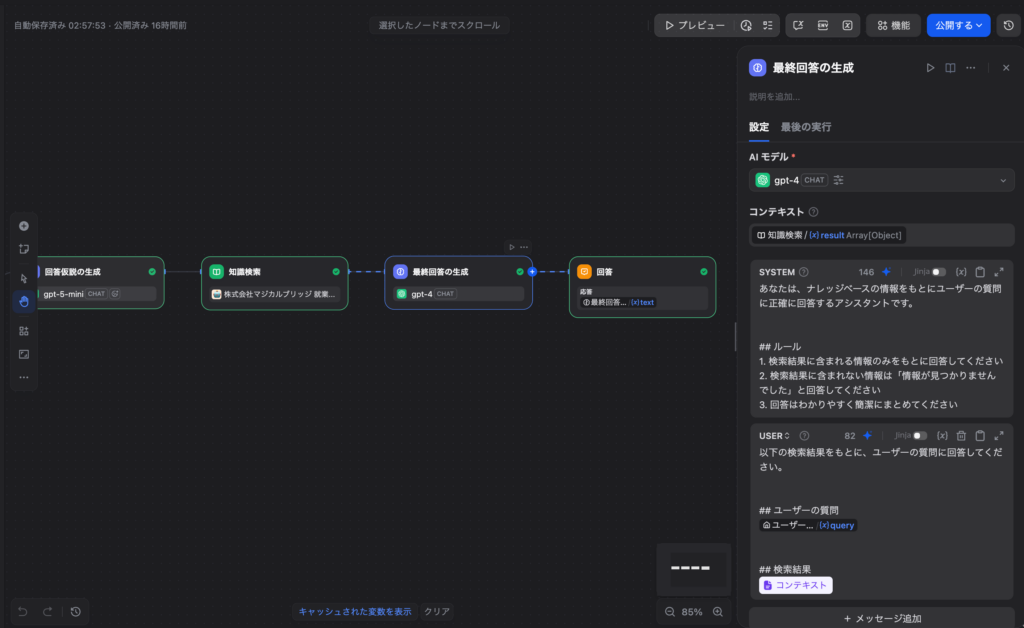
システムプロンプト:
あなたは、ナレッジベースの情報をもとにユーザーの質問に正確に回答するアシスタントです。
## ルール
1. 検索結果に含まれる情報のみをもとに回答してください
2. 検索結果に含まれない情報は「情報が見つかりませんでした」と回答してください
3. 回答はわかりやすく簡潔にまとめてくださいユーザープロンプト:
以下の検索結果をもとに、ユーザーの質問に回答してください。
## ユーザーの質問
{{#sys.query#}}
## 検索結果
{{#context#}}Step 6:終了ノードの設定
LLMノード②の出力を終了ノードに接続します。
ワークフロー完成形
[開始] → [LLMノード①: 仮説回答生成] → [ナレッジ検索: 仮説回答で検索] → [LLMノード②: 最終回答生成] → [終了]4. HyDE検索の精度検証
4.1 検証方法
同じナレッジベース(就業規則)と同じクエリで、以下の2つの方式を比較します。
従来RAG:[質問] → [ナレッジ検索] → [LLM回答]
HyDE: [質問] → [仮説回答生成] → [ナレッジ検索] → [LLM回答]4.2 テスト結果:実際の回答比較
就業規則のナレッジベースを使い、以下のクエリでテストしました。
テストクエリ
「休みって何日もらえるの?」
この質問は短く曖昧で、就業規則の中の「年次有給休暇」「休日」「特別休暇」など複数の条文にまたがる情報が必要です。
① 仮説回答の生成(LLMノード①の出力)
LLMノード①はナレッジベースを参照せず、LLMの一般知識をもとに「仮説的な回答文書」を生成します。この文書は検索クエリとして使うためのものであり、内容の正確性は問いません。そのため、LLMノード①で使うモデルは、GPT-4oではなくGPT-4o-miniで十分でした。仮説回答は「検索のヒント」として使うだけなので、高性能モデルでなくても検索精度に大きな差は出ません。コストを抑えたい場合はぜひ軽量モデルを試してみてください。
一般的に、日本の企業では年次有給休暇は入社後6か月経過時点で10日が付与され、勤続年数に応じて最大20日まで増加します。これに加え、夏季休暇、年末年始休暇、慶弔休暇などの特別休暇が設けられている場合があります。週休二日制の企業では土曜・日曜が所定休日となり、国民の祝日も休日に含まれるのが一般的です。
この仮説回答がベクトル化されてナレッジ検索のクエリになるため、「年次有給休暇」「特別休暇」「休日」といった就業規則の条文と高い類似度でマッチします。
② ナレッジ検索の結果
仮説回答で検索した結果、以下の条文がヒットしました。
- 第12条(年次有給休暇)
- 第9条(休日)
- 第13条(特別休暇)
③ 最終回答(LLMノード②の出力)
検索でヒットした条文をもとに、LLMノード②がナレッジに基づいた正確な回答を生成します。
年次有給休暇は勤続年数に応じて10日から20日まで付与されます。特別休暇もあり、結婚や出産、子の看護等の場合にはそれぞれ5日、3日、年5日(子が2人以上の場合は年10日)が付与されます。また、休日は土曜日、日曜日、国民の祝日、年末年始(12月29日から1月3日まで)、夏季休暇(8月13日から8月15日まで)、そして会社が指定する日です。
結果比較
| 評価項目 | HyDE | 従来RAG |
|---|---|---|
| 検索でヒットした条文 | 第12条、第9条、第13条(3条文) | 第9条(休日)のみ |
| 回答の網羅性 | ✅ 有給・休日・特別休暇を網羅 | ⚠️ 休日のみ回答 |
| 質問意図の理解 | ✅ 「休み」を多角的に解釈 | ❌ 「休日」のみに限定 |
従来RAGでは「休み」という曖昧な語と類似するチャンクが「休日」の条文に偏りましたが、HyDEでは仮説回答に「有給休暇」「特別休暇」「休日」がすべて含まれるため、関連する複数の条文を漏れなく検索できました。また、ナレッジのチャンクサイズも検索精度に影響します。今回は就業規則を条文単位(500〜800文字)で分割することで、HyDEの仮説回答との類似度が高くなりやすくなりました。チャンクが大きすぎるとノイズが増え、小さすぎると文脈が失われるので、まずは500文字前後で試してみるのがおすすめです。
4.3 HyDEが効果を発揮するケース
| ケース | 理由 |
|---|---|
| 短い・曖昧な質問 | 仮説回答で情報量を補完できるため |
| 専門用語を含まない質問 | LLMが専門用語を含む仮説文書を生成できるため |
| 「〜について教えて」型の質問 | 回答文書のスタイルに変換することで類似度が向上 |
4.4 注意すべきケース
| ケース | 理由 |
|---|---|
| 固有名詞の検索 | 「○○の電話番号は?」など、仮説回答で情報を補完しにくい |
| LLMの知識にないドメイン | 仮説回答の品質が下がり、検索精度に悪影響の可能性 |
| レイテンシが重要な場面 | 仮説回答生成の分だけ応答時間が増加する |
4.5 従来RAGとの使い分け
| 用途 | 推奨手法 | 理由 |
|---|---|---|
| 社内FAQ・マニュアル検索 | HyDE | 曖昧な質問が多く、仮説回答で補完効果が高い |
| 専門文書の検索 | HyDE | 専門用語の補完により検索精度が向上 |
| 固有名詞や数値の単純検索 | 従来RAG | 仮説回答の恩恵が少なく、待ち時間が増すだけ |
| リアルタイム応答が必要 | 従来RAG | LLMの追加呼び出し分の遅延を避けられる |
5. まとめ
- 課題: 質問文と回答文のスタイルの違いにより、従来のベクトル検索は精度が出にくい
- 解決策: HyDE=LLMで「仮説回答」を生成し、回答同士の類似度で検索する
- Difyでの実装: LLMノードで仮説回答を生成→その出力でナレッジ検索→最終回答生成
- 効果が高い場面: 曖昧な質問、専門用語がない質問、説明文型の回答が求められる場面
HyDEは既存のRAGパイプラインにLLMノードを1つ追加するだけで導入できる、費用対効果の高い改善手法です。まずはDifyのワークフローで試してみて、検索精度の変化を体感してください。
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
[👉 無料オンライン相談で、最適な導入プランを相談する]
参考文献
Gao, L., Ma, X., Lin, J., & Callan, J. (2022). “Precise Zero-Shot Dense Retrieval without Relevance Labels.” arXiv:2212.10496.
https://arxiv.org/abs/2212.10496
この記事を書いた人
関連記事
-
 DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド
DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド -
Claude CodeのAIスキルをDifyワークフローへ自動変換する【Workflow as Code実践ガイド】
-
Human-in-the-Loopの活用事例 Difyでの具体的な運用パターン9選
-
AIが自ら「検索し直す」。DeepSeek-R1とDifyが作る高度なRAG構築の最前線
-
【脱・OCR】Dify×VLMで、あらゆる画像・PDFを思い通りのJSONに変換する
-
Human-in-the-Loopの概念をDifyに落とし込み、AIの暴走を防ぐ安全設計を構築する
-
DifyのRAG精度を飛躍させる Contextual Retrieval構築マニュアル
-
最先端のGraphRAGの技術をDifyに落とし込み、最高精度なRAGを構築する







