
【脱・OCR】Dify×VLMで、あらゆる画像・PDFを思い通りのJSONに変換する

はじめに
業務システムへのデータ入力作業で、「PDFの見積書から手作業で金額を転記している」「従来のOCRツールを導入したが、表のレイアウトが崩れて結局手直しが必要…」といった悩みはありませんか?本記事を読めば、最新のVLM(視覚言語モデル)を活用し、画像や複雑なPDFドキュメントから人間と同等の精度で正確にデータを抽出・整理する方法が分かります。
従来のOCR(光学文字認識)技術は文字をテキスト化することには長けていましたが、請求書の複雑な表組みや、グラフの意味、資料のレイアウト(文脈)までを理解することは困難でした。
そこで現在、大きな注目を集めているのが「VLMによるドキュメント解析(Document Parsing)」です。本記事では、VLMの基本概念から、従来のOCRとの決定的な違い、そしてDifyをつかって実際にドキュメントから欲しいデータだけをJSON形式で抽出するワークフローの構築手順までを分かりやすく解説します。
💡この記事で分かること
- OCRの限界を解決するVLMの圧倒的優位性:従来のOCRで必須だった事前の「帳票テンプレート作成」はもう不要です。視覚と文脈の双方を理解するVLMなら、未知のレイアウトや複雑な表からでも人間レベルの精度で正確にデータを抽出できます。
- Difyによる自動化フロー構築:Difyの「パラメータ抽出ノード」をつかえば、どんな書式の請求書からでも、すぐに会計システムで使えるクリーンな数値・JSONデータを自動生成するAIを簡単に構築可能です。
1. VLM(視覚言語モデル)とは何か?
VLM(Vision-Language Model:視覚言語モデル)とは、テキストだけでなく「画像(視覚情報)」も同時に理解し、言語空間で処理できるAIモデルのことです。
代表的なモデルとして、OpenAIの「GPT-4o」や、Anthropicの「Claude 3.5 Sonnet」、Googleの「Gemini 1.5 Pro」などがあります。皆さんもChatGPT等に画像をアップロードして「この画像について説明して」と質問した経験があるかもしれませんが、まさにその裏側の技術がVLMです。
ドキュメント解析(Document Parsing)の文脈において、VLMは単に「画像に何が写っているか」を答えるだけでなく、「この請求書の合計金額はいくらか」「このグラフが示している右肩上がりのトレンドの要因は何か」といった、画像内の文字と視覚的なコンテキスト(文脈)を高度に紐づけて理解することができます。
1.1 なぜVLMはそのようなことが可能なのか?
従来のAIシステムは「画像認識モデル」と「自然言語処理モデル(LLM)」が完全に分断されていました。つまり、画像をテキストに変換(OCR)してから、言語モデルに渡すという二度手間を踏んでいたのです。
これに対し、最新のVLMは「画像の特徴」と「テキストの意味」を初めから同じ次元(ベクトル空間)の中で一緒に学習しています。
例えば、私たちが初めて見るお店のレシートを受け取った時、「合計」という文字を意識的に探さなくても、「一番下に大きく太字で書かれた数字」を見れば、それが支払うべきトータルの金額だと直感的に理解できますよね。
VLMもこれと全く同じように、膨大な学習データから「大きい文字」「右下に配置された数字」といった視覚的なレイアウト情報と、「それが何を表す数字なのか(=合計金額)」という言語的な意味をセットにして学習しています。
そのため、事前に読み取り位置を指定(帳票定義)しなくても、まるで人間が書類をざっと眺めてざっくりと構造を把握するのと同じアプローチで、未知のフォーマットからでも正確にデータを解釈できるのです。この「視覚的な位置関係」と「言語的な意味」の統合こそが、VLMの圧倒的な能力の源です。
2. 従来のOCR技術との違いとVLMの圧倒的なメリット
ドキュメントのデータ化といえば、これまで長く「OCR(光学文字認識)」が主役として使われてきました。しかし、ビジネスの現場では「思っていたより使えない」「結局手作業でのチェックと修正ばかり発生する」という不満も多く聞かれます。VLMの登場により、このデータ抽出のパラダイムが根本から大きく変化しようとしています。
2.1 従来型OCRの”現場のリアルな限界”
従来のOCRはあくまで「画像の中にある文字の形(ピクセル配列)を認識して、テキストデータに変換する」技術に過ぎません。そのため、現場の実運用では以下のような高いハードルが存在していました。
- フォーマットへの極度な依存:
事前定義型(テンプレート型)のOCRでは、「A社の請求書はこの座標(X:100, Y:200)に金額がある」「B社は右上に日付がある」という帳票定義の事前登録作業が必須でした。取引先が100社あれば100パターンのテンプレートを作成・保守する必要があり、取引先がフォーマットを少し変えただけでエラーが頻発します。 - レイアウト崩れと表計算の弱さ:
段組みのある専門的な資料や、行や列が不規則に結合された請求書の「明細表(テーブル)」を読み込むと、文字の順序が縦横入り乱れてめちゃくちゃになり、システムに取り込めるデータ構造になりません。 - 文脈の非理解(文字は読めても意味は分からない):
OCRは「1」「0」「0」「0」という文字は読めても、それが「小計」なのか、「消費税」なのか、「総合計」なのか、前後の文脈から判断する能力を持っていません。結果として、間違った数字をシステムに渡してしまうリスクが常にありました。
2.2 VLMによるドキュメント解析の3つの強み
一方、これまで述べてきたように「視覚と意味」を統合しているVLMを使うことで、旧来のOCRの課題を一気に解決できます。
| 強み | 従来OCRの課題 | VLMがもたらす革新的なメリット |
|---|---|---|
| 完全フォーマットフリー (帳票定義が一切不要) | 事前の厳密な座標設定やテンプレート登録、フォーマット変更時のメンテナンスが膨大な負担だった。 | AIが人間のように「文字の意味」と「レイアウト上の位置関係」から視覚的に情報を探して読み取るため、初めて取引する会社の未知の書式の請求書や、スマホで歪んで撮影されたレシートでも即座に対応可能。導入初日から稼働できます。 |
| 複雑な表(テーブル)や グラフの文脈理解 | セルの結合や、不規則な明細行などがあると順番が崩れ、読み取りエラーの温床だった。 | 表の構造や罫線の意味、インデントの深さなどを視覚的に捉え、正しい関係性を維持したままJSON形式やマークダウン形式で出力できる。さらに「この棒グラフの一番高い月はどこか」といった図表の意図も読み取れます。 |
| 手書き文字やかすれの 高度な推測能力 | スキャン時のノイズ、ハンコのかぶり、少しでも文字が潰れていると記号化(文字化け)して読めなかった。 | VLMは「文字の形」だけでなく「前後の文脈」から総合的に判断します。例えば「1○,000円」の○がかすれていても、小計や消費税の計算式から「ここに入るのは0であるべきだ」と推論するため、人間でも読みづらいノイズに対して非常に高い精度を誇ります。 |
2.3 VLMによるドキュメント解析の具体的な業務活用例
これらの強みを活かし、VLMはこれまで手作業に頼らざるを得なかった以下のような複雑な業務プロセスを次々と自動化しています。
- 多種多様なフォーマットの請求書・領収書処理(経理部門)
- 課題: 取引先ごとにレイアウトがバラバラで、従来のOCRではテンプレート設定が追いつかない。
- VLMの活用: どんな書式で送られてきても、VLMが「会社名」「インボイス登録番号」「税率ごとの金額」などを判断して抽出し、会計システム(SaaS)へ自動入力するAPI連携フローを構築。
- 専門的な図面や複雑な間取り図の読み取り(不動産・建設業界)
- 課題: スキャンされた図面PDFの中に記載されている「建て坪」「設備仕様」などのテキストが図形や線と被っており、OCRでは文字化けしてしまう。
- VLMの活用: 線と文字が重なっていても、「ここは寸法を表す数字だ」とコンテキストを理解して正確に値をピックアップし、物件データベースのスペック表を自動生成。
- 手書きの問診票やアンケートのデータ化(医療・小売業界)
- 課題: 顧客がフリーフォーマットで書いた手書きの感想や、チェックボックスのレ点が枠からはみ出していると判定できない。
- VLMの活用: くせのある手書き文字も「文脈」から高精度に読み解き、さらに「自由記述の感想」をその場で「ポジティブ/ネガティブ」に感情分析してタグ付けする処理までも同時に実行。
これらはほんの一例ですが、「画像から文字を起こす」だけでなく「内容を理解して必要な形に整理する」というプロセスまで一気に完結できるのがVLMの最大の魅力です。
3. 実践:DifyとVLMを使ったドキュメントデータ抽出ワークフロー
それでは、Difyを使って実際に「アップロードされた請求書の画像から、必要な項目(会社名、日付、合計金額など)だけを抽出し、システム連携しやすいJSON形式で出力する」ワークフローを構築してみましょう。
ワークフロー全体像
[開始:ユーザー入力(画像ファイルのアップロード)]
↓
[パラメータ抽出(VLM):画像を解析し、指定した項目を抽出する]
↓
[終了:抽出したデータ(JSON等)を出力、または後続のAPIへ渡す]3.1 Step 1:開始ノードの設定(ファイルアップロード)
Difyで「ワークフロー」タイプのアプリを作成し、一番最初の開始ノードを設定します。
VLMに画像を渡すため、入力フィールドとしてファイルを受け取れるようにします。
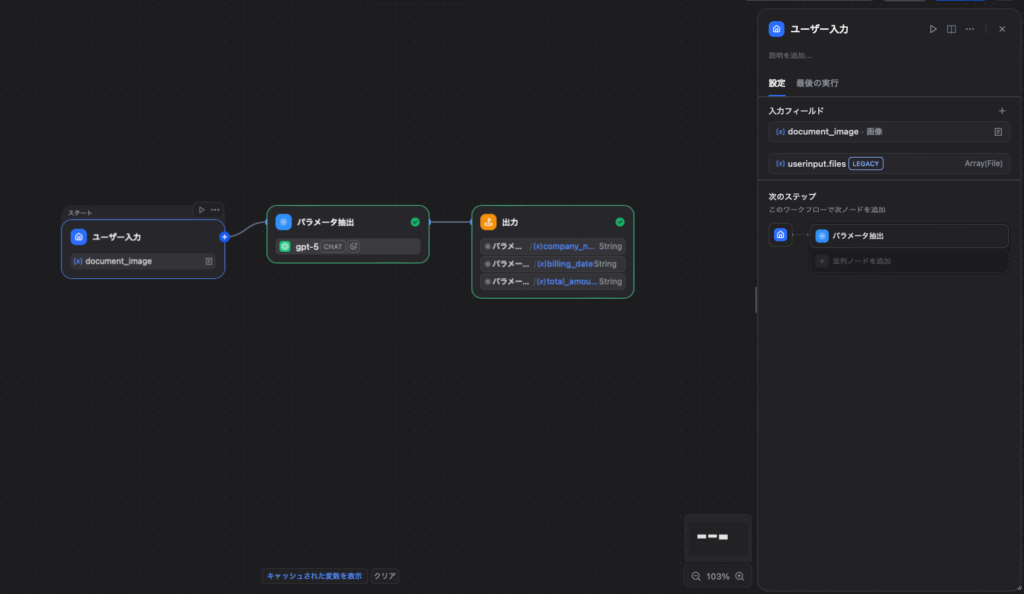
- フィールドタイプ:
ファイル(File)または画像(Image) - 変数名:
document_imageなど - これにより、ユーザーが画面上から請求書などの画像をアップロードできるようになります。
3.2 Step 2:VLMの力を引き出す「パラメータ抽出」ノード
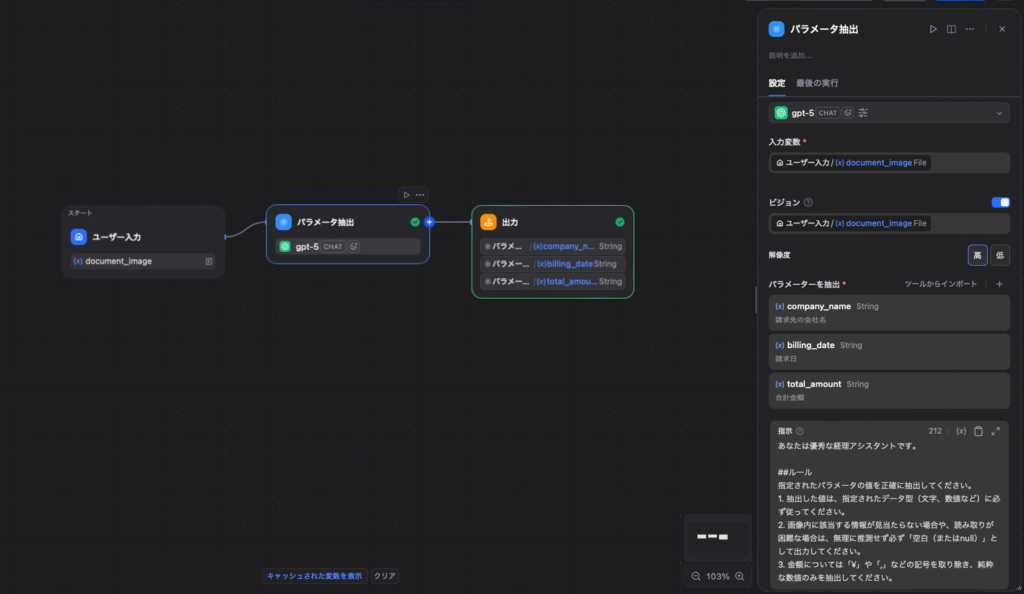
- ノードの追加: 開始ノードの次に「パラメータ抽出」ノードを追加し、指定したフォーマットで情報を抽出させます。
- モデルの選択: GPT-4o や Claude 3.5 Sonnet など、Vision対応(画像認識モード)のモデルを選択します。(※モデル横に目のアイコンや「Vision」の記載があるもの)
- 入力変数の設定とビジョン(画像認識)の有効化:
設定画面には、画像を受け取るための2つの専用項目が並んでいます。両方ともに、開始ノードで受け取った画像変数( 例:document_image (File))をセットします。- 入力変数: これにセットすることで、下の「指示」プロンプト内で画像データを参照できるようになります。
- ビジョン: こちらのスイッチをオンにし、変数をセットすることで「この画像をVLMとして視覚的に解析する」というフラグが立ちます。
- 抽出パラメータの定義:
このノードの強みは、「何を抽出したいか」を変数として定義するだけで、AIが自動でJSON化してくれる点です。画面上で以下のパラメータを追加します。company_name(String: 請求先の会社名)billing_date(String: 請求日)total_amount(Number: 合計金額)
- 指示(プロンプト)の作成:
パラメータ抽出ノードには「システム」や「ユーザー」といった区分けはなく、「指示(Instruction)」という1つの入力欄のみが存在します。
実務でそのままコピー&ペーストして使える形式のプロンプトを以下に設定します。(Difyの仕様上、画像変数は専用の入力UIから渡すことも多いですが、テキストでの指示も併記すると正確性が増します)あなたは優秀な経理アシスタントです。
##ルール 指定されたパラメータの値を正確に抽出してください。
1. 抽出した値は、指定されたデータ型(文字、数値など)に必ず従ってください。
2. 画像内に該当する情報が見当たらない場合や、読み取りが困難な場合は、
無理に推測せず必ず「空白(またはnull)」として出力してください。
3. 金額については「¥」や「,」などの記号を取り除き、純粋な数値のみを抽出してください。
💡変数の挿入方法(画像で操作されている箇所)
【抽出対象の画像】の下にある/(半角スラッシュ) を入力すると、変数の選択メニューが立ち上がります。そこから「ユーザー入力」の中にあるdocument_image (File)をクリックして挿入してください。
3.3 Step 3:出力(抽出結果の活用)
「パラメータ抽出」ノードから得られた情報は、綺麗に構造化されたデータとしてそのまま後続のステップで利用できます。
フローの最後に「出力」ノード(チャットフローの回答ノード、ワークフローの終了ノード等)を繋ぎ、ユーザーや外部アプリへ返すための変数を定義します。
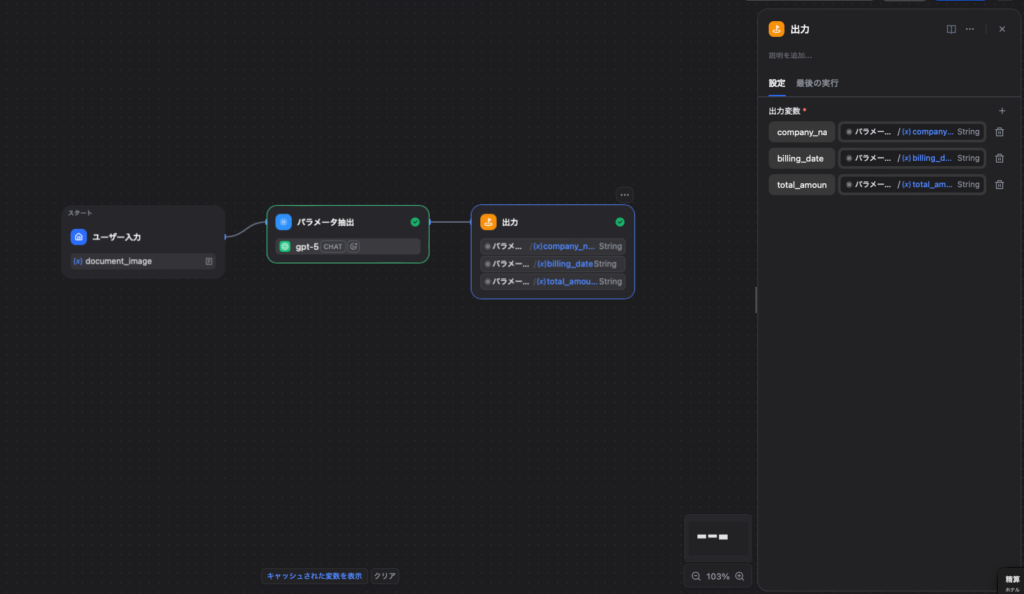
【出力変数の定義方法(画像の設定例)】
出力ノードの設定画面にある「出力変数」にて、+ボタンから以下の3つの変数を追加します。
それぞれ、値の入力欄で / を入力し、パラメータ抽出 ノードのドロップダウンから対応する項目を選択・挿入してください。
- 変数名:
company_name- 値:
パラメータ抽出 > {x} company_name (String)
- 値:
- 変数名:
billing_date- 値:
パラメータ抽出 > {x} billing_date (String)
- 値:
- 変数名:
total_amount- 値:
パラメータ抽出 > {x} total_amount (String)
- 値:
💡 実務での応用:
単に画面に出力するだけでなく、この出力ノードの前に「HTTPリクエスト」ノードを挟めば、抽出したデータをそのまま自社の経理システム(SaaS)のAPIへ送信したり、kintoneなどのDBへ自動連携させるといった高度な業務自動化プロセスが即座に構築できます。
3.4 実際の検証結果(Test Run)
実際に、サンプルの請求書画像を用いてDifyでテスト実行(Test Run)を行った結果がこちらです。
【テストに使用した請求書データ】
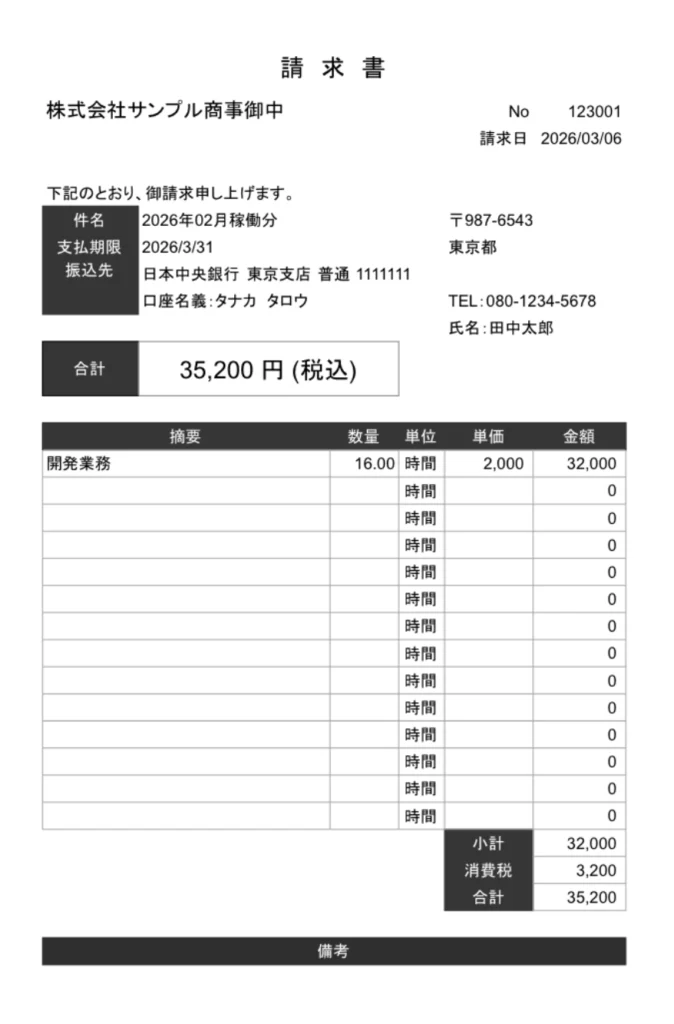
- 請求先の会社名: 株式会社サンプル商事
- 請求日: 2026/03/06
- 合計金額: 35,200 円 (税込)
【Difyでの抽出結果】
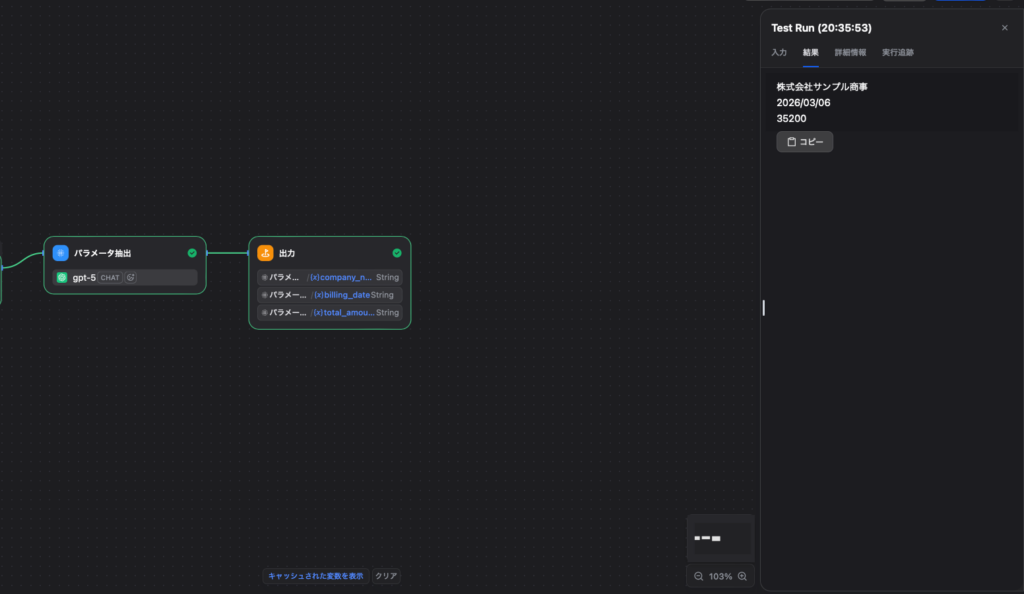
company_name:株式会社サンプル商事billing_date:2026/03/06total_amount:35200
プロンプトのルールで「純粋な数値のみを抽出してください」と指定したおかげで、画像内では「35,200 円 (税込)」と表記されている部分から、カンマや円記号が綺麗に除去されました。
これにより、後続のシステム(会計ソフトやデータベースなど)でそのまま扱えるクリーンな数値データ(35200)として、一瞬で正確に抽出できていることがわかります。
これで、「どんなフォーマットの請求書が来ても、正しく必要な情報を抜き出し、システムで利用できる形式に変換してくれるAI」の完成です!
4. VLMを利用する際のデメリットと注意点
VLMによるドキュメント解析は、従来のOCRの常識を覆すほど極めて強力ですが、決して「魔法の杖」ではありません。実運用に乗せてビジネスの現場で活用するためには、VLM特有のデメリット(弱点)を正しく理解し、それを補うためのシステム設計が必要不可欠です。
【デメリット1】API連携コスト(トークン消費)の増大
VLMは画像を高解像度で解析するほど、細かい文字や表の罫線を正確に捉えることができるため抽出精度が劇的に上がります。しかし、そのぶんAPIのコスト(トークン消費量)は跳ね上がります。従来の安価なOCRツールと比較すると、1枚あたりの処理単価が数倍〜十数倍になるケースも珍しくありません。
- 【Tips】コストと精度のトレードオフ設計:
大量のドキュメントを定常的に処理するシステムを組む場合、全件を高解像度でVLMに投げるのは現実的ではありません。事前に複数の解像度でテストを行い、「許容できるコスト」と「業務に耐えうる最低限の読み取り精度」の最適なバランスを見極めるチューニングが必須です。
【デメリット2】処理速度(レイテンシ)の遅さ
GPT-4oやClaude 3.5 Sonnetなどの強力なVLMは、その高度な推論能力ゆえに、1枚の画像を解析して結果を返すまでに数秒〜十数秒の時間がかかります。ユーザーが画面上でアップロードして「即座(1秒以内)に結果を返す」ようなリアルタイム性が求められる要件には不向きです。
- 【Tips】非同期処理と一括バッチ処理の活用:
数十ページに及ぶPDF資料からデータを抽出する場合、すべてを直列で待つとタイムアウトエラーを引き起こす可能性があります。Difyのループ処理などを用いてバックグラウンドで非同期に処理を進めたり、夜間に一括でバッチ処理を走らせるような「少し待てる業務フロー(非同期アーキテクチャ)」に着地させるのが成功の秘訣です。
【デメリット3】幻覚(ハルシネーション)によるデータ汚染リスク
VLMもベースは大規模言語モデル(LLM)であるため、不鮮明な文字や手書きのノイズなどを「もっともらしい別の文字」として完全に誤認して出力してしまうリスク(ハルシネーション)が常に存在します。金額が1桁違えば大問題になるようなクリティカルなデータを扱う場合、AIを完全に盲信するのは危険です。
- 【Tips】重層的な安全網(チェック機構)の構築:
抽出項目の中にプロンプトで「自信度(Confidence score: 0〜100)」を出力させ、一定スコア以下の場合はシステムの自動登録をストップさせる仕組みが有効です。また、「小計」+「消費税」=「合計」になるかの計算チェックを後続のロジックで自動化したり、最終的に人間が目視でワンクリック承認する「Human-in-the-Loop」のプロセスをDifyに組み込むことが実運用では強く推奨されます。
「Human-in-the-Loop」に関する記事はこちらから

【デメリット4】機密情報のクラウド送信(セキュリティへの懸念)
OpenAIやAnthropicなどのAPIを利用する場合、請求書に記載された顧客の個人情報や、社外秘の図面データが外部のクラウドサーバーに送信されることになります。(※API経由のデータは学習に利用されない規約になっていることがほとんどですが、社内のセキュリティポリシー上、送信自体がNGとされるケースもあります)
- 【Tips】マスキング処理とローカルVLMの検討:
個人情報が含まれる領域をアップロード前に黒塗り(マスキング)する前処理を挟むか、または完全に自社環境からデータを出さない要件であれば、オープンソースのローカルVLM(Llama 3.2-Visionなど)を自社サーバーに構築してDifyと連携させるというアプローチも視野に入ってきます。
5. まとめ
- 課題: 従来のOCRは、決まった帳票フォーマットに依存し、複雑な表やレイアウトの意図までは読み取れないという限界があった。
- 解決策: VLM(視覚言語モデル)を使えば、事前のテンプレート登録なしで、画像の意味や文脈を理解しながら人間レベルの精度でデータを抽出できる。
- Difyでの実装: 「パラメータ抽出ノード」×「Vision対応モデル」を組み合わせることで、どんなバラバラの書式の画像からでも、一瞬で綺麗なJSONデータを抽出する仕組みがノーコードで作れる。
これまで「どうしても手作業で転記するしかなかった」非定型フォーマットの書類業務こそ、VLMの独壇場です。Difyを使って、圧倒的な業務効率化の第一歩を踏み出してみませんか?
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
👉 無料オンライン相談で、最適な導入プランを相談する
この記事を書いた人
関連記事
-
 DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド
DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド -
Claude CodeのAIスキルをDifyワークフローへ自動変換する【Workflow as Code実践ガイド】
-
Human-in-the-Loopの活用事例 Difyでの具体的な運用パターン9選
-
AIが自ら「検索し直す」。DeepSeek-R1とDifyが作る高度なRAG構築の最前線
-
Human-in-the-Loopの概念をDifyに落とし込み、AIの暴走を防ぐ安全設計を構築する
-
DifyのRAG精度を飛躍させる Contextual Retrieval構築マニュアル
-
RAG検索精度の革命|HyDEの理論からDify実装・検証まで完全解説
-
最先端のGraphRAGの技術をDifyに落とし込み、最高精度なRAGを構築する







