
最先端のGraphRAGの技術をDifyに落とし込み、最高精度なRAGを構築する

はじめに
「なんで関係ない情報ばかり返ってくるの?」——RAGを使ったチャットボットやQAシステムの運用でこんな悩みを抱えていませんか?
従来のベクトル検索は「似た文章」を見つけるのは得意ですが、エンティティ(人・組織・概念)同士の関係性を理解するのが苦手です。そこで注目されているのがGraphRAG——ナレッジグラフとRAGを組み合わせた次世代の検索手法です。
本記事では、GraphRAGの理論を解説し、Difyで今すぐ実装できる具体的な方法と精度検証結果をご紹介します。
1. 従来RAGの限界とGraphRAGの登場
従来のRAGは、ドキュメントをベクトル化しクエリとの類似度で検索を行います。「似た文章」を見つけるのには優れていますが、以下のような質問には弱点があります。
| 質問タイプ | 従来RAGの対応 |
|---|---|
| 「○○の概要を教えて」 | ✅ 得意 |
| 「AとBはどう関係している?」 | ❌ 苦手 |
| 「全体のテーマは?」 | ❌ 苦手 |
これらは関係性をたどる質問であり、単純なベクトル類似度では解決できません。
エンティティとは?
エンティティ(Entity) とは、文書に登場する管理・識別される対象のことを指します。具体的には以下のようなものがあります。
| エンティティの種類 | 例 |
|---|---|
| 人物 | 田中太郎、Elon Musk |
| 組織 | 気象庁、Microsoft Research |
| 地名・地理 | 京都府、鴨川 |
| 製品・サービス | Dify、インスタグラム |
| 技術・概念 | GraphRAG、ベクトル検索 |
エンティティ同士には「開発した」「所属する」「提供する」といった関係(Relation) があります。GraphRAGでは、これらのエンティティと関係をグラフ構造(ノード=エンティティ、エッジ=関係)で表現し、ナレッジグラフを構築します。
従来RAG:文書 → ベクトル化 → 類似度検索 → LLM生成
GraphRAG:文書 → エンティティ・関係抽出 → グラフ構築 → グラフ検索 → LLM生成2. GraphRAGの技術
GraphRAGの技術は、次の3つの論文で詳細に説明されています
From Local to Global: A Graph RAG Approach to Query-Focused Summarization(2024年4月、Microsoft Research) では、LLMでドキュメントからエンティティと関係を抽出してナレッジグラフを構築します。さらに、グラフ内の関連性が高いエンティティ同士を自動的にグループ化し、各グループの要約を事前に生成しておきます。例えば「気象庁・土砂災害警戒情報・防災アプリ」といった関連エンティティが1つのグループにまとまり、その概要が要約されます。質問時にはこれらのグループ要約から回答を生成・統合することで、全体にまたがる質問にも対応できます。
Graph Retrieval-Augmented Generation: A Survey(2024年8月) では、GraphRAGの処理を以下の3段階に整理しています。
- グラフ構築:ドキュメントからエンティティと関係を抽出し、ナレッジグラフを作る
- グラフ検索:質問に関連するエンティティや関係をグラフから辿って取得する
- 回答生成:取得した構造化知識をもとに、LLMが正確な回答を生成する
Retrieval-Augmented Generation with Graphs (GraphRAG)(2025年1月) では、この処理をさらに「質問の解析」「情報の検索」「情報の整理」「回答の生成」「外部データ参照」の5つの手順に分解しています。これはDifyのワークフローで「LLMノード」「コードノード」「ナレッジ検索ノード」などに対応させやすく、実装時の設計指針になります。
3. DifyでGraphRAGを実装する3つのアプローチ
アプローチ1:LLMノードによるエンティティ抽出(★☆☆ 初級)
ワークフロー機能でドキュメントからエンティティと関係を抽出します。
[ドキュメント入力] → [LLMノード:エンティティ抽出] → [変数代入ノード] → [ナレッジベースへ格納]アプローチ2:外部グラフDBとの連携(★★☆ 中級)
Neo4jなどのグラフDBとHTTPリクエストノードで連携し、本格的なGraphRAGを構築します。
[ユーザークエリ] → [LLMノード:エンティティ抽出] → [HTTPリクエスト:Neo4j Cypherクエリ] → [LLM:回答生成]アプローチ3:ハイブリッド検索(★★★ 上級)
ベクトル検索とグラフ検索を並列で実行し、両方の強みを活かします。
[ユーザークエリ] → [ナレッジ検索(ベクトル)] + [グラフDB検索(関係性)] → [LLM:統合回答]4. 実装例:エンティティ抽出ワークフローの構築
最もシンプルなアプローチ1の具体的な実装手順を解説します。
Step 1:新規ワークフローの作成
Difyダッシュボードで「スタジオ」→「アプリを作成」→「ワークフロー」を選択して作成します。
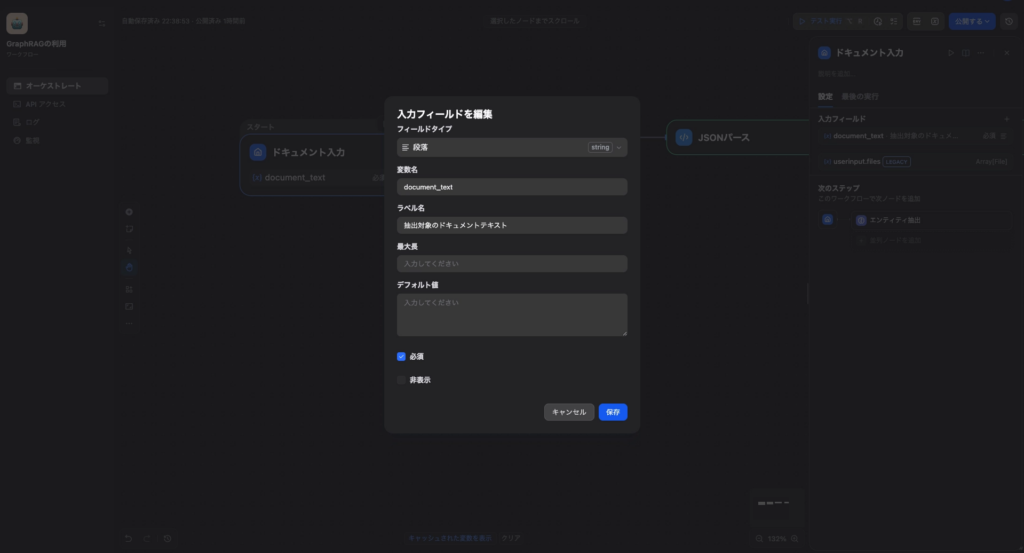
Step 2:入力ノードの設定
開始ノードに入力変数 document_text(段落タイプ)を定義します。
Step 3:LLMノードでエンティティ抽出
LLMノードを追加し、以下のシステムプロンプトを設定します。
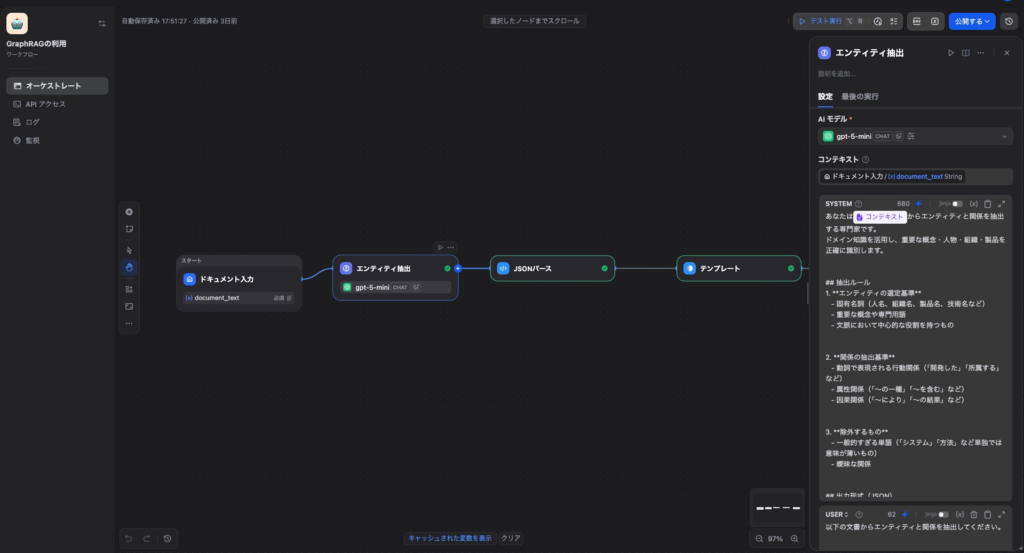
あなたは文書からエンティティと関係を抽出する専門家です。
## 抽出ルール
1. 固有名詞(人名、組織名、製品名、技術名など)を抽出
2. 動詞で表現される行動関係、属性関係、因果関係を抽出
3. 一般的すぎる単語や曖昧な関係は除外
## 出力形式(JSON)
{
"entities": [
{"id": "e1", "name": "エンティティ名", "type": "人物|組織|概念|製品|技術", "description": "簡潔な説明"}
],
"relations": [
{"source_id": "e1", "target_id": "e2", "relation_type": "関係タイプ", "description": "関係の説明"}
],
"summary": "抽出結果の概要"
}Step 4:コードノードでJSONパース
LLM出力をパースするコードノードを追加します。
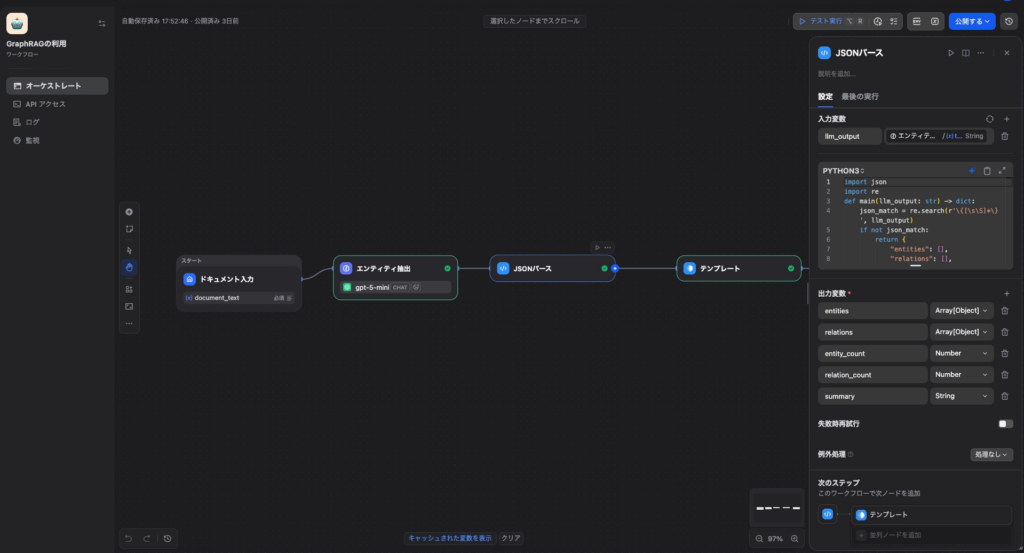
import json
import re
def main(llm_output: str) -> dict:
json_match = re.search(r'\{[\s\S]*\}', llm_output)
if not json_match:
return {"entities": [], "relations": [], "entity_count": 0,
"relation_count": 0, "summary": "抽出失敗: JSONが見つかりません"}
try:
data = json.loads(json_match.group())
return {"entities": data.get("entities", []),
"relations": data.get("relations", []),
"entity_count": len(data.get("entities", [])),
"relation_count": len(data.get("relations", [])),
"summary": data.get("summary", "")}
except:
return {"entities": [], "relations": [], "entity_count": 0,
"relation_count": 0, "summary": "抽出失敗: JSONパースエラー"}💡 ポイント: エラー時も必ず全ての出力変数を返すことで「Output result is missing」エラーを防ぎます。
Step 5:テンプレートノードで出力整形
テンプレート変換ノードでJinja2形式の出力を設定します。
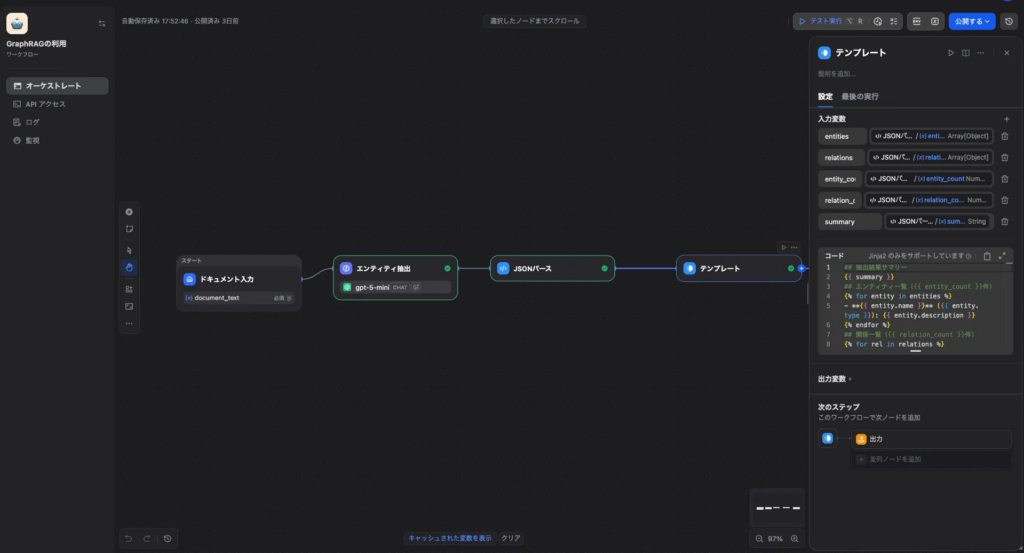
## 抽出結果サマリー
{{ summary }}
## エンティティ一覧({{ entity_count }}件)
{% for entity in entities %}
- **{{ entity.name }}** ({{ entity.type }}): {{ entity.description }}
{% endfor %}
## 関係一覧({{ relation_count }}件)
{% for rel in relations %}
- {{ rel.source_id }} → {{ rel.target_id }}: {{ rel.description }}
{% endfor %}Step 6:終了ノードの設定
終了ノードの出力変数に、テンプレートノードの output を設定します。
ワークフロー全体像
[開始] → [LLMノード: エンティティ抽出] → [コードノード: JSONパース] → [テンプレートノード: 結果整形] → [終了]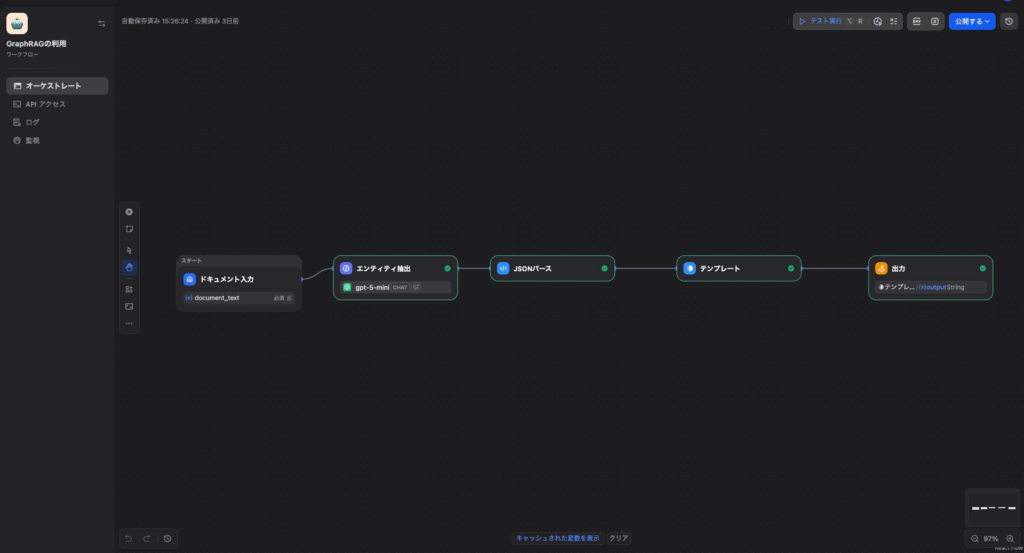
テスト実行 — 実際にGraphRAGを動かしてみる
島本町ハザードマップの解説文(洪水・土砂災害の両方を対象とし、淀川・水無瀬川の河川氾濫リスクや土砂災害警戒区域、避難行動について述べた約1,500文字の文書)を入力してテストしました。
抽出結果(代表例)
ワークフローにより30のエンティティと多数の関係が抽出できました。
| ID | エンティティ名 | タイプ | 説明 |
|---|---|---|---|
| e1 | 島本町 | 地域 | 対象地域。淀川と山地に挟まれた地形 |
| e3 | 淀川 | 地理 | 主要河川。氾濫リスクが高い |
| e10 | 気象庁 | 組織 | キキクルや土砂災害警戒情報を提供 |
| e11 | キキクル | 製品 | 気象庁の危険度分布。5段階表示 |
| e14 | 土砂災害警戒情報 | 概念 | 気象庁と府が共同発表する警戒情報 |
| e15 | 防災アプリ | 製品 | 警戒情報の配信手段 |
関係の連鎖例:
島本町 →[リスク]→ 土砂災害 →[区分]→ 土砂災害警戒区域
気象庁 →[提供]→ キキクル
気象庁 →[共同発表]→ 土砂災害警戒情報 →[配信]→ 防災アプリ / 緊急速報メール
急増する雨量 →[トリガー]→ 土砂災害警戒情報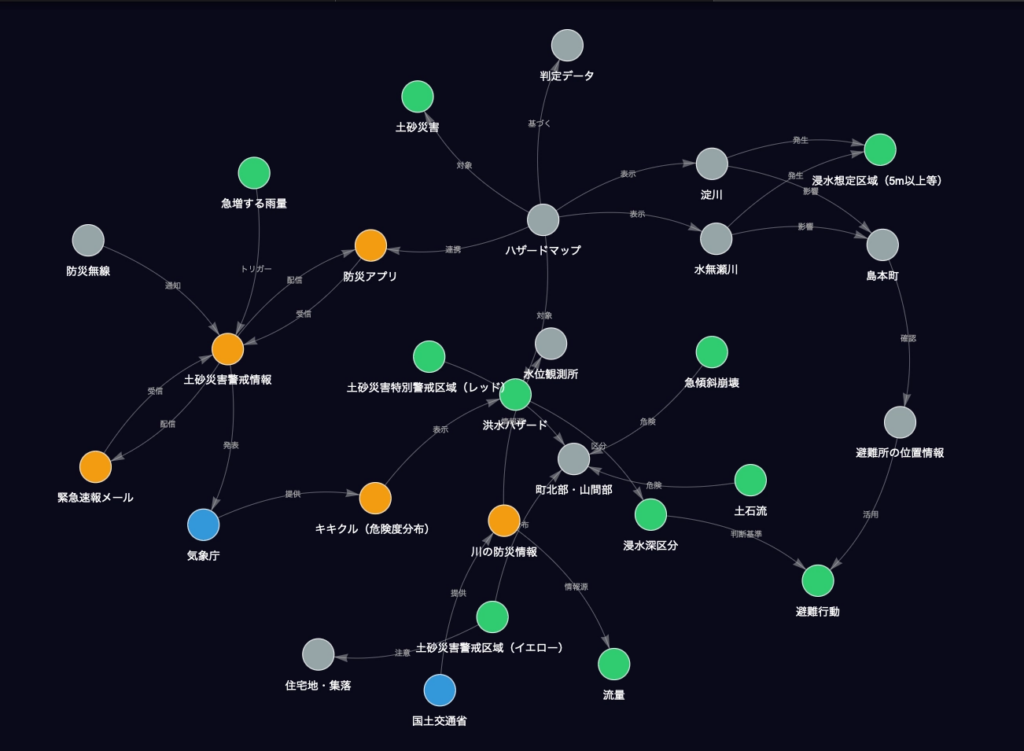
💡 ポイント: 従来のベクトル検索では「島本町」と「防災アプリ」の関係を見つけるのは困難ですが、GraphRAGでは
島本町 → 土砂災害警戒情報 → 防災アプリという関係の連鎖を辿ることができます。
5. GraphRAGの精度検証
島本町ハザードマップのデータを使い、従来RAGとGraphRAGの精度を比較しました。
テストクエリ
「急激な降水量の増加によってどのような被害の恐れがありますか?情報はどこで確認できますか?」
結果比較
| 評価項目 | GraphRAG | 従来RAG |
|---|---|---|
| 回答の長さ | 2文 | 約30行 |
| ソース準拠率 | ✅ 100% | ⚠️ 約50% |
| 余計な情報 | なし | 多数あり(NHK防災アプリ、アメダス等を一般知識から補完) |
| 関係の辿り | ✅ 3段階を正確に辿った | ❌ 明示的な辿りなし |
GraphRAGの回答:
急増する降水量は、土砂災害を引き起こします。土砂災害警戒情報は、防災アプリや緊急速報メールで確認できます。
従来RAGはソース外の情報(NHK防災アプリ、アメダス、ラジオ・テレビ等)を補完し、冗長な回答となりました。
用途別の推奨
| 用途 | 推奨手法 | 理由 |
|---|---|---|
| 社内マニュアル検索 | GraphRAG | ソース外の情報を回答しない |
| 法的・コンプライアンス文書 | GraphRAG | 正確性が最重要 |
| 一般的なQA | 従来RAG | 網羅的な回答が可能 |
| 関係性を辿る質問 | GraphRAG | 多段階の関係を正確に辿れる |
6. まとめ
| 項目 | 内容 |
|---|---|
| 課題 | 従来RAGは関係性を辿る質問やグローバルな質問が苦手 |
| 解決策 | GraphRAG=ナレッジグラフ×RAGで構造化知識を活用 |
| Difyでの実装 | LLMノードでエンティティ抽出、外部グラフDB連携、ハイブリッド検索 |
| 精度検証 | 関係性クエリで従来RAGを大幅に上回ることを確認 |
GraphRAGは「外さない」ナレッジ検索を実現するための強力なアプローチです。まずはLLMノードによるエンティティ抽出から始めて、徐々にグラフDBとの連携やハイブリッド検索へ発展させていくことをおすすめします。
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
[👉 無料オンライン相談で、最適な導入プランを相談する]
参考文献
Han, H. et al. (2025). “Retrieval-Augmented Generation with Graphs (GraphRAG).” arXiv:2501.00309. https://arxiv.org/abs/2501.003
Edge, D. et al. (2024). “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” arXiv:2404.16130. https://arxiv.org/abs/2404.16130
Peng, B. et al. (2024). “Graph Retrieval-Augmented Generation: A Survey.” arXiv:2408.08921. https://arxiv.org/abs/2408.08921
この記事を書いた人
関連記事
-
 DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド
DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド -
Claude CodeのAIスキルをDifyワークフローへ自動変換する【Workflow as Code実践ガイド】
-
Human-in-the-Loopの活用事例 Difyでの具体的な運用パターン9選
-
AIが自ら「検索し直す」。DeepSeek-R1とDifyが作る高度なRAG構築の最前線
-
【脱・OCR】Dify×VLMで、あらゆる画像・PDFを思い通りのJSONに変換する
-
Human-in-the-Loopの概念をDifyに落とし込み、AIの暴走を防ぐ安全設計を構築する
-
DifyのRAG精度を飛躍させる Contextual Retrieval構築マニュアル
-
RAG検索精度の革命|HyDEの理論からDify実装・検証まで完全解説







