
AIが自ら「検索し直す」。DeepSeek-R1とDifyが作る高度なRAG構築の最前線

はじめに
社内でRAG(検索拡張生成)システムを構築したものの、「質問が少し複雑になると、的外れな回答が返ってくる」「検索結果に欲しい情報がないのに、AIが無理やり嘘の回答(ハルシネーション)を作ってしまう」といった壁にぶつかっていませんか?
従来のRAGは「検索して、そのまま回答する」という一直線のプロセス(Naive RAG)であったため、検索精度がそのまま回答品質の限界になっていました。
そこで現在、AI開発の最前線で注目を集めているのが、「自己改善型RAG(Self-Reflective RAG)」です。本記事では、世界中を驚かせた超強力な推論モデル「DeepSeek-R1」と、ノーコードAI構築ツール「Dify」を掛け合わせ、AI自身が「今の検索結果で回答できるか?」を考え、足りなければ自ら再検索を行うプロトタイプの構築手順を解説します。
🚀 本記事のサマリー(結論)
- 「考えるAI」DeepSeek-R1の衝撃:従来のLLMとは異なり、回答前に「内省(思考プロセス)」を挟む推論モデル(Reasoning Model)を使えば、RAGの精度と論理性が劇的に向上します。
- Difyによる自己改善ループの実装:検索結果を鵜呑みにせず、AI自身が「情報不足」と判断したら検索クエリを書き換えて再検索に向かう「自己反省ループ」を備えた高度なRAGシステムが、ノーコードで構築可能です。
この記事で分かること
- DeepSeek-R1に代表される「推論モデル(Reasoning Model)」の特徴と強み
- 従来のRAG(Naive RAG)の限界と、「自己改善型RAG(Self-Reflective RAG)」の仕組み
- Difyのチャットフローを用いた、自己改善型RAGの具体的な構築ステップ
- 推論モデルを実運用に組み込む際のレイテンシ(遅延)やコストに関する注意点
1. DeepSeek-R1と「推論モデル(Reasoning Model)」の衝撃
2025年初頭、中国のAIスタートアップDeepSeek社が発表した「DeepSeek-R1」は、AI業界に強烈なインパクトを与えました。その最大の理由は、OpenAIの「o1」などに代表される推論モデル(Reasoning Model)でありながら、圧倒的な低コスト(およびオープンソース)で同等以上の性能を叩き出したためです。
従来のLLMと何が違うのか?
従来のLLM(GPT-4oやClaude 3.5 Sonnetなど)は、入力に対して「最も自然な次の単語」を即座に出力する仕組みでした。
一方、DeepSeek-R1のような推論モデルは、最終的な回答を出力する前に「内省(Chain of Thought:思考の連鎖)」のプロセスを強制的に挟みます。
内部で「このユーザーの質問の真の意図は何か?」「まずAを考えて、次にBを検証しよう」「いや、待てよ。この前提は間違っているかもしれないから修正しよう」といった論理的な試行錯誤(自己反省)を行ってから回答を生成します。
この「立ち止まって深く考える」能力こそが、複雑な条件分岐や評価が必要な高度なRAGシステムにおいて、かつてない威力を発揮するのです。
2. 「自己改善型RAG(Self-Reflective RAG)」とは何か?
自己改善型RAGとは、 検索して回答するだけの一方通行なRAGとは異なり、「取得した情報が本当に質問に答えるには十分か?」をAI自身が判断し、不十分であれば検索クエリを自動で書き換えて再検索するという「自己反省(Self-Reflection)のループ」を持ったRAG構造のことです。人間が調べ物をする際に「このキーワードではヒットしないな、別の言い方で調べ直そう」と考えるプロセスを、AIが自律的に行います。
従来型RAGの限界(Garbage In, Garbage Out)
従来の標準的なRAG(Naive RAG)は、以下のような一直線のフローでした。ユーザーの質問 → ベクトルデータベースを検索 → 検索結果と質問をLLMに渡す → LLMが回答を作成
この構成の最大の弱点は、「検索結果の質が悪ければ(Garbage In)、回答の質も必然的に悪くなる(Garbage Out)」ことです。LLMは与えられたコンテキストの中で無理やり回答を作ろうとしてハルシネーションを起こすか、安易に「わかりません」と答えて終わってしまいます。
自己改善型RAG(Self-Reflective RAG)のアプローチ
そこで登場したのが、人間のリサーチャーと同じように「情報が足りなければ、検索キーワードを変えてもう一度調べる」という自己反省(Self-Reflection)のループを組み込んだRAGアーキテクチャです。
- 検索(Retrieve): まず検索する。
- 評価(Grade/Reflect): 取得した情報が、ユーザーの質問に答えるのに十分か?を推論モデルが評価する。
- 分岐(Route):
- 十分(YES)なら → 最終回答を作成して終了。
- 不十分(NO)なら → なぜ不十分かを自己分析し、検索クエリ(キーワード)を書き換えて再度検索(1)に戻る。
この「評価」と「クエリの再構築」という難易度の高いタスクにおいて、深く思考できるDeepSeek-R1が最高のパフォーマンスを発揮します。
従来型RAG(Naive RAG)との違い
| 比較項目 | 従来型RAG(Naive RAG) | 自己改善型RAG(Self-Reflective RAG) |
|---|---|---|
| 検索回数 | 1回のみ | 情報が揃うまで自律的に複数回 |
| 情報不足時の挙動 | そのまま無理やり回答 → ハルシネーション | 自分で「情報不足」と判断して再検索 |
| クエリの柔軟性 | ユーザーが入力したキーワードのみ | AI自身が別の視点でキーワードを再構築 |
| 複雑な質問への対応 | ❌ 難しい(複数ドキュメントにまたがる質問に弱い) | ◎ 得意(複数ソースを自律的に探索・統合) |
| ハルシネーションリスク | 高い(情報が足りなくても答えようとする) | 低い(情報がなければ「見つかりません」と返す) |
| 必要なモデル | 通常のLLMで可 | 推論モデル(Reasoning Model)が最適 |
| 処理速度 | 速い(1回のみ) | 遅い(思考に数十秒かかる) |
従来のRAGは検索の1回勝負であるのに対し、自己改善型RAGは「考えながら調べ直す」という人間のリサーチプロセスを模倣しています。
具体的なユースケース(社内規程の複合検索)
この「自己反省」が実業務でどう活きるのか、具体例で見てみましょう。
【ユーザーの質問】
「来月、フルリモートから週3日出社に切り替わります。通勤手当の申請方法と、PCモニターを自宅からオフィスに持ち込む際のセキュリティ申請の手続きを教えてください。」
- 従来のRAG(Naive RAG)の場合
「出社 通勤手当 PCモニター」などで一度だけ検索し、最初にヒットした『通勤手当支給規程』の一部だけを読んで回答を生成します。結果として「通勤手当は~」とは答えられますが、PCモニターの持ち込みに関する『情報セキュリティガイドライン』のページを見つけられず、「モニターについては記載がありませんでした」と回答して終わってしまいます。 - 自己改善型RAG(Self-Reflective RAG)の場合
- まず初回の検索結果から『通勤手当支給規程』を取得します。
- DeepSeek-R1が取得情報を評価し、「通勤手当の答えはあるが、『PCモニター持ち込みの申請手続き』に関する情報が不足しており、このままではユーザーの質問に完全には答えられない」と自ら気づきます。
- 自動で「私物PC備品 持ち込み セキュリティ申請」といった全く新しいクエリを推論・再構築して再検索を行います。
- 必要な規程がすべて手元に揃ったことを確認(YES)してから、ユーザーの複数の質問に完璧に答える最終回答を生成します。
このように、複数の要素が絡み合った複雑な質問に対しても途中で諦めず、「ユーザーに完璧な回答を返すためのピースが揃うまで自律的に探し続ける」ことができるのが、自己改善型RAGの最大の魅力です。
3. 実践:Dify × DeepSeek-R1で作る自己改善型RAGのチャットフロー
では、Difyの「チャットフロー(Chatflow)」機能を使って、この「自己改善型RAG」のプロトタイプを構築してみましょう。チャット画面で実際のやり取りをテストできるため、この用途に最適です。
チャットフロー全体像
[開始]
↓
[知識検索(ナレッジベースから初回検索)]
↓
[LLM (DeepSeek-R1): 文脈の評価(Grade)]
↓
[条件分岐(IF/ELSE)]
├─ (YES: 情報が十分) ──> [LLM: 最終回答の生成] ──> [終了]
│
└─ (NO: 情報が不十分) ─> [LLM: クエリの書き換え] ──> [知識検索(再検索)] ──> (評価へ戻る ※Difyのループノードを活用)(※注: 実際のDifyのUIでは無限ループを避けるため、ループノードを活用するか、最大再検索回数を設定する設計にします)
Step 1:知識検索(ナレッジベースからの初回検索)
まず、ユーザーからの質問(sys_query)を使ってナレッジベースを検索し、関連する情報を取得します。
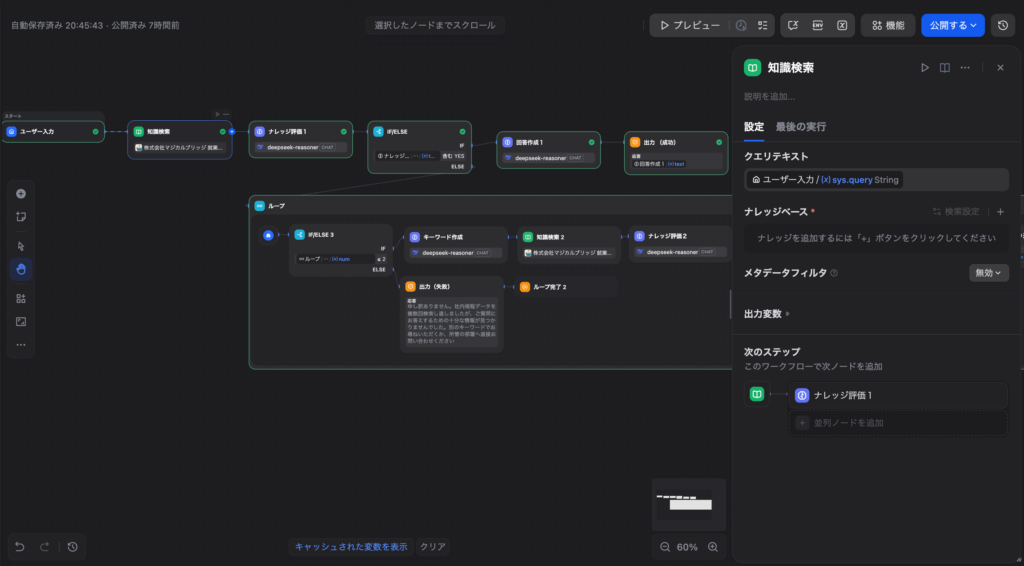
Step 2:DeepSeek-R1による文脈の「評価」
次に、Step 1で取得した検索結果(context)をDeepSeek-R1に渡し、「この情報だけでユーザーの質問に回答可能か?」を評価させます。
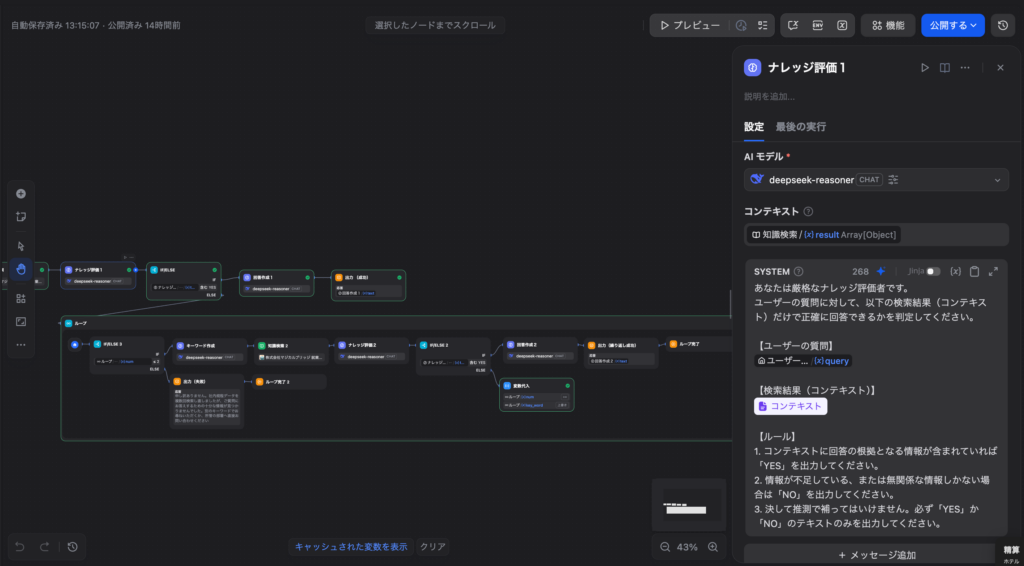
【評価用プロンプトの例(DeepSeek-R1)】
あなたは厳格なナレッジ評価者です。
ユーザーの質問に対して、以下の検索結果(コンテキスト)だけで正確に回答できるかを判定してください。
【ユーザーの質問】
{{ sys_query }}
【検索結果(コンテキスト)】
{{ context }}
【ルール】
1. コンテキストに回答の根拠となる情報が含まれていれば「YES」を出力してください。
2. 情報が不足している、または無関係な情報しかない場合は「NO」を出力してください。
3. 決して推測で補ってはいけません。必ず「YES」か「NO」のテキストのみを出力してください。Step 3:条件分岐(IF/ELSE)ノードの設定
DeepSeek-R1の出力結果(YES or NO)を受け取り、フローを分岐させます。
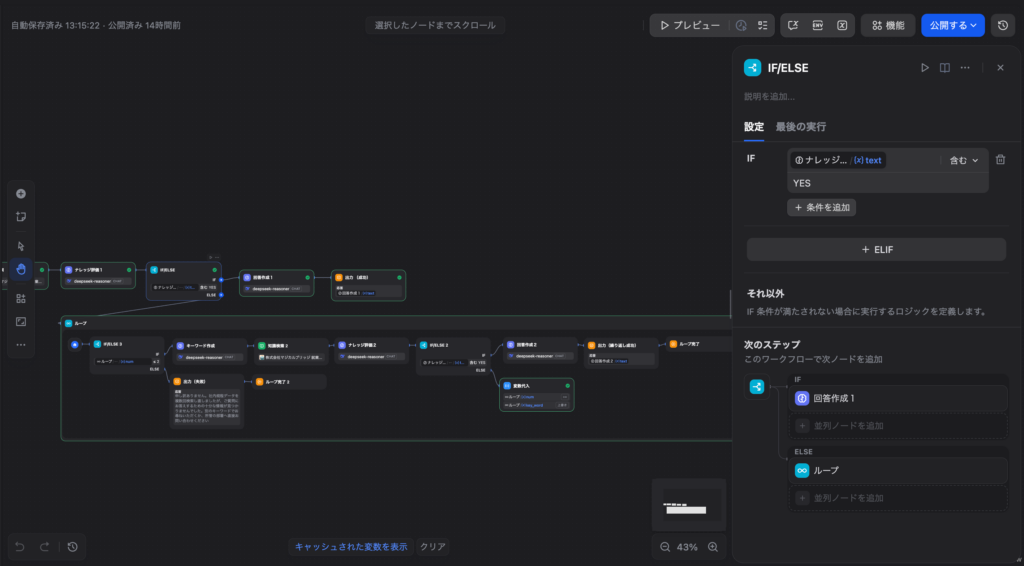
- 条件1(IF): 変数が
YESを含む場合 → Step 5(最終回答の生成)へ - 条件2(ELSE): それ以外(NOの場合) → Step 4(クエリ再構築)へ
Step 4:クエリの書き換えと再検索(自己改善ループ)
評価が「NO(情報不足)」だった場合、単に諦めるのではなく、もう一つの「LLMノード」を使ってDeepSeek-R1に「なぜ見つからなかったのか、どう検索し直すべきか」を推論させます。
ここでDifyの「ループノード」を活用するのがポイントです。Difyのチャットフローは原則として処理を逆行(前へ戻る)させることができませんが、ループノード内に次の処理を格納することで、指定された回数だけ「自己反省ループ」を回すことができます。
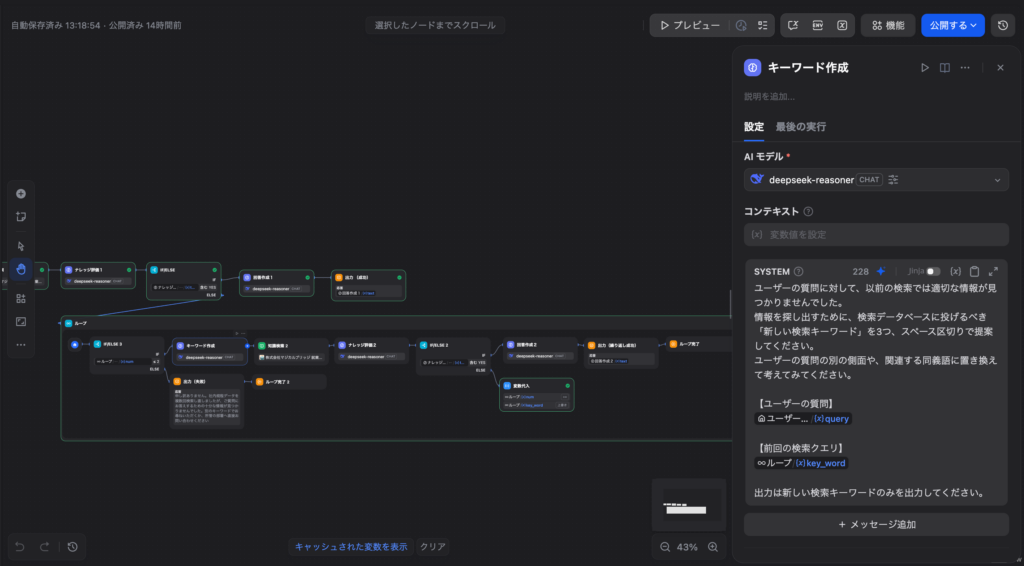
【クエリ書き換え用プロンプトの例(LLMノード)】
ユーザーの質問に対して、以前の検索では適切な情報が見つかりませんでした。
情報を探し出すために、検索データベースに投げるべき「新しい検索クエリ(キーワード)」を3つ程度、スペース区切りで提案してください。
ユーザーの質問の別の側面や、関連する同義語に置き換えて考えてみてください。
【ユーザーの質問】
{{ sys_query }}
出力は新しい検索キーワードのみを出力してください。ここでDeepSeek-R1が算出した「新しいキーワード」という変数を使って、ループ内の「知識検索ノード」を再度実行させます。
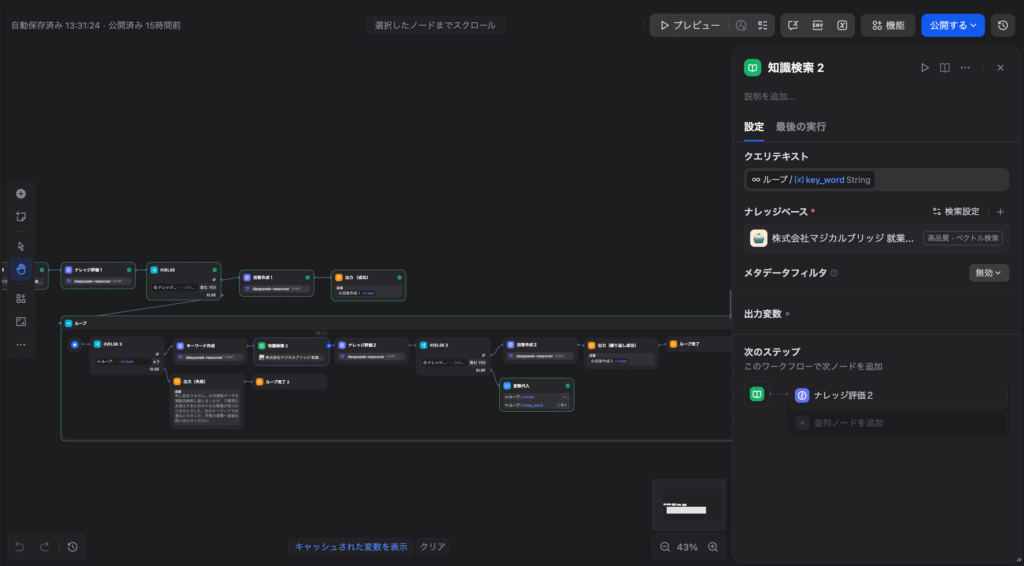
【ループノードの内部構成について】
📝 Note: 本記事はあくまで「Self-RAG(自己改善型RAG)」の概念と実装プロトタイプに焦点を当てているため、ループノード自体の詳細な仕様や設定方法については深く触れません。ループノードの詳細については、別途Difyの公式ドキュメントをご参照ください。
ループノードはただ繰り返すだけのノードではなく、その内部に「1回の再検索サイクル」に必要な処理を全て格納したミニフローを作る仕組みです。以下のスクリーンショットで確認できる通り、ループの内部は以下の流れで構成されています。
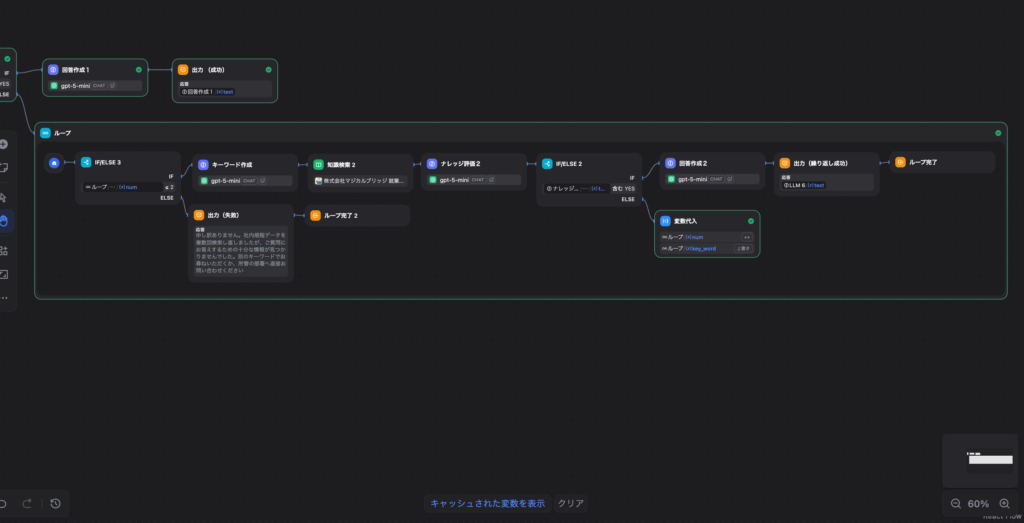
- IF/ELSE(ループ回数チェック): ループが何周目かを確認し、上限回数(例:2回)に達していたら即座に出力(失敗)へ分岐します。
- キーワード作成(LLMノード): 前回の検索が失敗した理由を踏まえ、DeepSeek-R1が新しい検索キーワードを生成します。
- 知識検索 2(知識検索ノード): 生成した新しいキーワードでナレッジベースを再検索します。
- ナレッジ評価 2(LLMノード): 再検索の結果が十分かをDeepSeek-R1が再度評価します。
- IF/ELSE 2(結果の判定):
- YES(情報が十分): → 「回答作成2」で最終回答を生成し、「出力(繰り返し成功)」から「ループ完了」へ進みます。
- NO(まだ不十分): → 「変数代入」ノードでループカウンターをインクリメント(+1)し、次のループ周回へ戻ります。
なお、ループノードについては「最大ループ回数」の上限を設定することができます。設定した回数を使い切った場合でも情報が見つからなかった場合は、ループの外へ抜け出し、次のStep 6(フェイルセーフ)へと処理が流れます。
Step 5:最終回答の生成
十分な情報(コンテキスト)が集まったら、最後に「LLMノード」(ここもDeepSeek-R1や、速度重視ならGPT-4o等でも可)を配置し、集めた情報を元にユーザー向けの読みやすい回答を作成させて完了です。
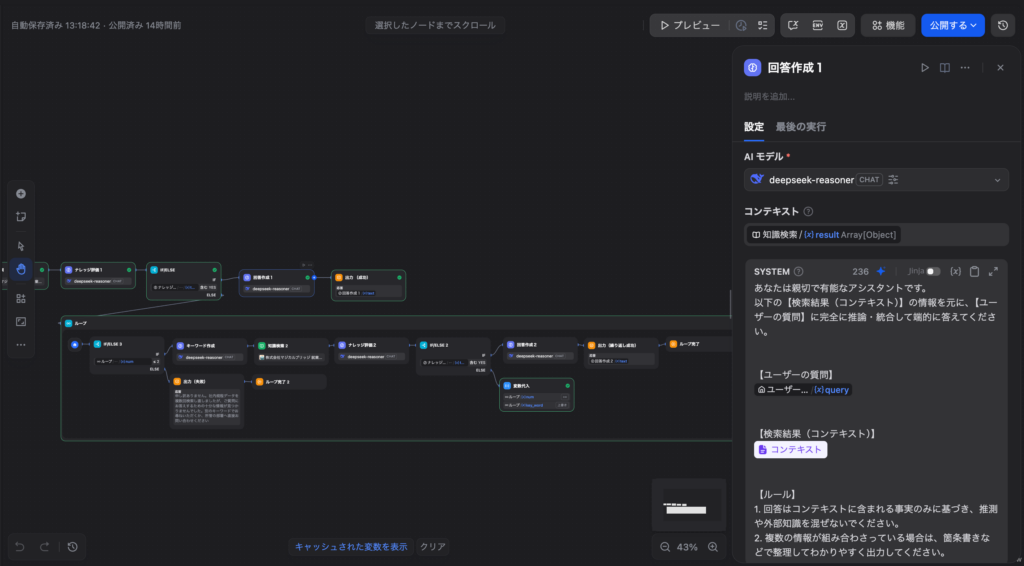
【最終回答用プロンプトの例(LLMノード)】
あなたは親切で有能なアシスタントです。
以下の【検索結果(コンテキスト)】の情報を元に、【ユーザーの質問】に完全に推論・統合して端的に答えてください。
【ユーザーの質問】
{{ sys_query }}
【検索結果(コンテキスト)】
{{ context }}
【ルール】
1. 回答はコンテキストに含まれる事実のみに基づき、推測や外部知識を混ぜないでください。
2. 複数の情報が組み合わさっている場合は、箇条書きなどで整理してわかりやすく出力してください。Step 6:検索に失敗した場合のフェイルセーフ(安全装置)
指定した回数(例:2回)のループを繰り返しても、ナレッジベースから必要な情報が一切見つからなかった場合の出力も設計しておきましょう。
ループノードを最後まで完走してしまった(途中で「YES」のルートに分岐できなかった)場合は、最後に「回答ノード」へ繋ぎ、ユーザーに対して以下のような定型メッセージを出力して処理を終了させます。
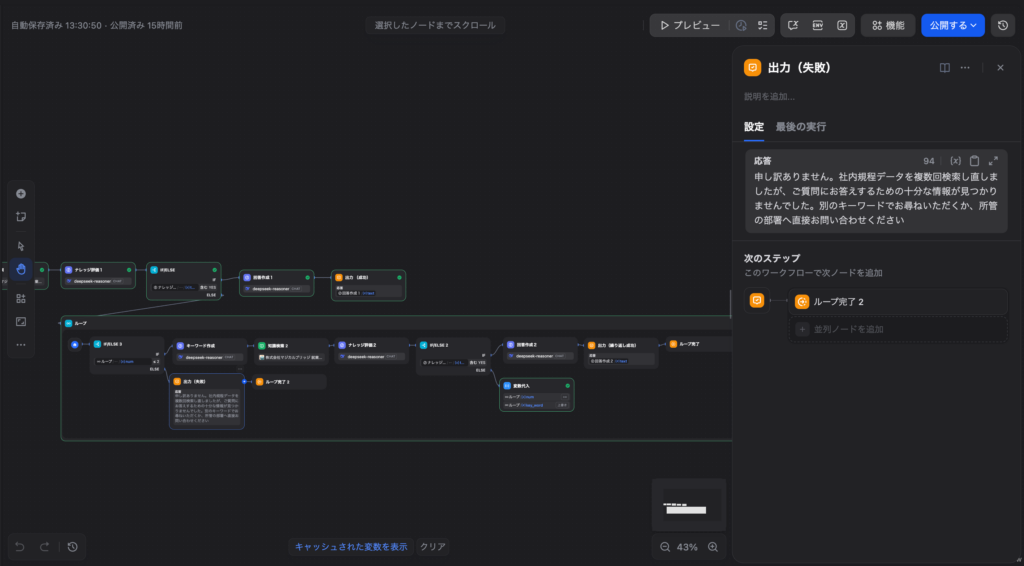
【検索失敗時の出力メッセージ例】
「申し訳ありません。社内規程データを複数回検索し直しましたが、ご質問にお答えするための十分な情報が見つかりませんでした。別のキーワードでお尋ねいただくか、所管の部署へ直接お問い合わせください。」
このように、「わからない時は無理に嘘(ハルシネーション)をつかず、これ以上検索しても無駄だと判断して正直に謝る」というフローを明示的に組めるのも、Difyを使った自己改善型RAGの非常に大きな利点です。
実際のテスト実行結果
構築したチャットフローをDifyのプレビュー機能でテストした実際の動作結果を見てみましょう。
テスト①:意図を読み解いて回答できるか(成功パターン)
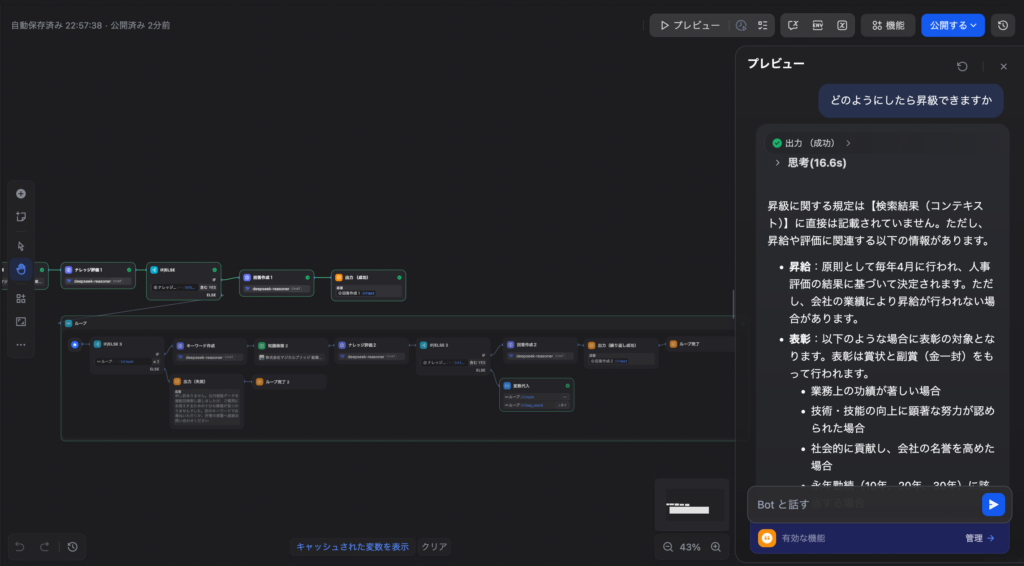
ユーザー入力:「どのようにしたら昇級できますか」
「昇級」という言葉が規程に直接記載されていなくても、DeepSeek-R1が「昇給・人事評価・表彰」という関連ドキュメントを自律的に収集・統合して回答を生成しました。思考時間は約16秒。推論モデルが自己反省ループを回しながら情報の過不足を判断していることが分かります。
テスト②:ナレッジベース外の質問に正直に答えるか(フェイルセーフパターン)
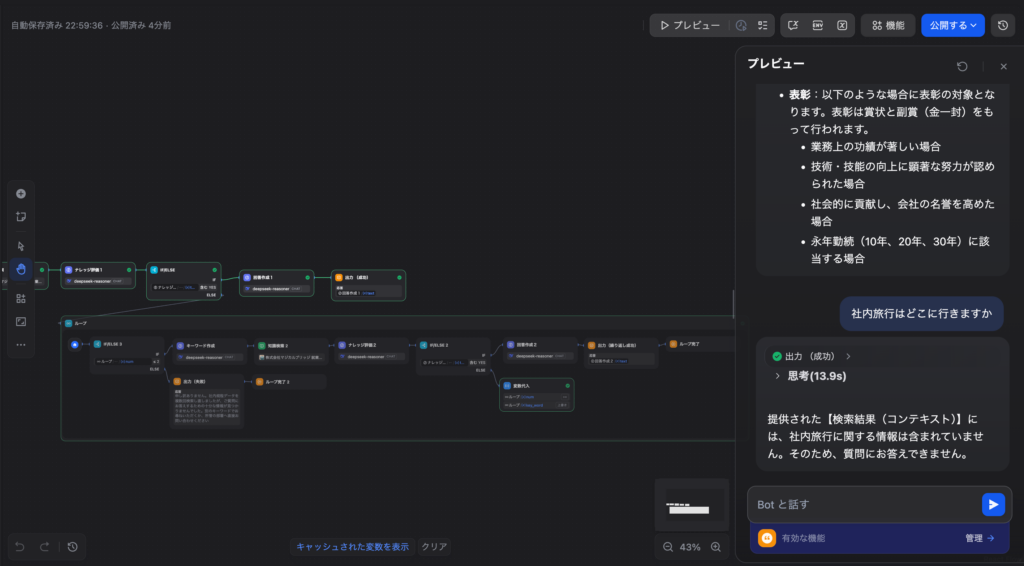
ユーザー入力:「社内旅行はどこに行きますか」
ナレッジベース内に存在しない「社内旅行」についての質問に対し、ハルシネーション(嘘の回答)を一切生成することなく「提供された情報の中には含まれていません」と明確に返答しました。思考時間は約14秒。ループを回した上で「これ以上検索しても意味がない」と判断してフェイルセーフが正常に機能しています。
4. 推論モデルをRAGに組み込む際のデメリットと注意点(Tips)
DeepSeek-R1を用いた自己改善型RAGは非常に強力ですが、実運用にはいくつかの壁があります。
【注意点1】応答速度(レイテンシ)の大幅な低下
推論モデル最大のデメリットは「回答が遅い」ことです。DeepSeek-R1は回答前に内部で数十秒ほど「思考」するため、チャットボットのように「すぐに返事が欲しい」ユースケースには不向きです。
- 【Tips】役割分担と非同期UI: 評価やクエリ書き換えフェーズなど「裏側のロジック」には推論モデルを使い、ユーザーと直接やり取りする部分にはGPT-4oなどの高速モデルを組み合わせる。また、UI側で「現在データベースを再検索しています…」といったステータス表示を出し、体感的な待ち時間を減らす工夫が必要です。
【注意点2】トークン消費とコストの増大
推論モデルは「思考プロセス(Chain of Thought)」自体が大量の出力トークンを消費します。APIを利用する場合、想定外にコストが膨らむ可能性があります。
- 【Tips】ローカルLLMの活用: オープンソースであるDeepSeek-R1(または軽量化された蒸留モデル)をローカル環境(自社サーバーやOllamaなど)でホスティングすれば、APIコストを気にせず、この重厚な自己反省ループを何度でも回すことが可能になります。
【注意点3】無限ループの防止
「評価」→「再検索」のループを組む場合、求める情報がそもそもナレッジベース内に存在しないケースでは永遠にループし続けてしまいます。
- 【Tips】リトライ上限の設定: チャットフローを設計する際、再検索の回数を「最大2回まで」などの上限(Max retries)を必ず設け、それを超えたら「該当データが存在しません」と返す安全装置を組み込んでください。
【注意点4】学習データの汚染リスク
もし学習データの中にノイズや誤った「反省・評価プロセス」の例が含まれていた場合、AIが間違った自己評価基準を学習してしまい、検索ループ全体が破綻するリスク(学習データ汚染)がつきまといます。
- 【Tips】定期的な監査体制の構築:AIの「自己評価の基準」が本当に正しい状態を保てているか、システム単体で完結させず、定期的に出力ログや反省プロセスを人間がモニタリングし、微細な基準のズレを修正し続ける運用体制(MLOps)の構築が必要です。
5. 自己改善型RAGが真価を発揮するシーン
DeepSeek-R1を用いた自己反省ループは強力ですが、1回の回答までに数十秒の「思考時間」と計算コストがかかります。そのため、「今日のランチのおすすめは?」のような単純な質問(即答性が求められるチャット)には適していません。
逆に、「多少時間がかかっても、絶対に正確で網羅的な回答が欲しい業務」において、圧倒的な費用対効果を生み出します。
シーン①:技術仕様書やAPIドキュメントの横断検索(エンジニア向けサポート)
- 課題:開発者が「エラーコードXが出た時の、新APIへの移行手順を教えて」と質問した場合、旧仕様書、新仕様書、障害対応マニュアルなど複数のドキュメントに情報が散らばっています。
- Self-RAGの強み:AIが一度の検索で諦めず、「まず新仕様書を読んで…記載がないなら、次にエラーコード一覧を検索し直そう」と自律的に複数ソースを探索・統合して、完全な手順書を生成してくれます。
シーン②:過去の類似トラブル・保守履歴からの原因究明(カスタマーサポート・製造現場)
- 課題:「製品Aから異音がして、電源ランプが赤く点滅している」という複雑な症状に対し、製品マニュアルだけでなく、過去数万件のトラブル対応履歴(チケット)から該当する事例を探す必要があります。
- Self-RAGの強み: 「ランプの点滅」だけで検索して関係ない情報がヒットした場合、「異音という条件も追加して再検索すべきだ」とAIが推論(自己評価)し、熟練のサポーターがキーワードを変えながら調べるのと同じプロセスを自動で実行してくれます。
シーン③:契約書・法務ガイドラインのリスクチェック(法務・管理部門)
- 課題:「この業務委託契約書の第5条は、下請法の最新のガイドラインに違反していないか?」といった高度なリーガルチェック。
- Self-RAGの強み: 単なるキーワード一致ではなく、「契約書の第5条の内容」と「下請法の禁止事項」を照らし合わせるという複雑な論理展開が必要です。DeepSeek-R1の推論能力を用いれば、「この条文はAと解釈できるが、ガイドラインのBに照らすとリスクがある。念のためCの判例も検索して確認しよう」といった深い洞察と追加検索を行い、精度の高いリスクチェックレポートを出力します。
6. まとめ
本記事では、従来のRAGが抱えていた「検索結果の質がそのまま回答の限界になる」という根本的な課題に対し、DeepSeek-R1のような推論モデル(Reasoning Model)を活用した「自己改善型RAG(Self-Reflective RAG)」がいかにしてその壁を突破できるかを解説しました。
従来型のRAGでは、ユーザーの質問に対してベクトルデータベースを1回検索し、取得した情報をそのままLLMに渡して回答を生成するという一方通行のフローが一般的でした。しかし、この構成では検索結果に欲しい情報が含まれていなかった時点で回答品質が破綻し、ハルシネーションや的外れな回答が頻発するという問題がありました。自己改善型RAGは、この「1回の検索で全てが決まってしまう」という構造的な弱点を、AI自身に「検索結果を評価させ、不十分であれば自らキーワードを変えて再検索する」という自己反省ループを組み込むことで解決します。
そして、このような高度なエージェント的挙動を、Difyのチャットフローとループノードを使えばノーコードで可視化しながら構築・テストできることも実証しました。
- 課題:従来のRAGは検索精度に依存しており、複雑な質問には対応できずハルシネーションを起こしやすかった。
- 解決策:DeepSeek-R1のような「推論モデル(Reasoning Model)」を用いた「自己改善型RAG(Self-Reflective RAG)」を採用し、情報不足時に自らクエリを書き換えて再検索する「思考ループ」を構築する。
- Difyでの実装:Difyのチャットフロー(条件分岐やループ処理)を使えば、この高度で複雑なエージェント的挙動もノーコードで可視化しながら実装・テストが可能。
- 従来型RAGで十分なケース:FAQ対応や単一ドキュメント内の情報検索など、質問と回答が1対1で対応づく単純なユースケースでは、従来型RAG(Naive RAG)で十分に高い精度が得られます。応答速度・コスト面でも有利です。
- 自己改善型RAGが必要なケース:複数ドキュメントの横断検索、曖昧な質問への対応、専門用語の言い換えが求められる法務・技術サポートなど、「1回の検索では正解にたどり着けない」複雑な業務シーンでは、自己改善型RAGの推論・再検索ループが真価を発揮します。
「検索して答えるだけ」の時代は終わり、これからは「AIが自ら考え、納得するまで調べてから答える」自律型エージェントの時代です。DeepSeek-R1とDifyの組み合わせは、その未来を最も手軽に体験できる最強のコンビネーションと言えるでしょう。
最後に
私たちは、単にシステムを組むだけの開発会社ではありません。低コストで高品質なAIツールの構築から、ROI(投資対効果)を最大化する導入ロードマップの策定、社内スタッフが自らAIを運用・改善できる体制の構築まで、AI導入の成功に必要なすべてを最初から最後まで丸ごと支援いたします。
実は、ご相談いただく方のほとんどが「何が分からないかも分からない」という状態からのスタートです。構想段階でも、ただのアイデアベースでも構いません。
まずは、あなたのお困りごとをそのまま聞かせていただけませんか?貴社のビジネスを加速させるパートナーとして伴走いたします。
👉 無料オンライン相談で、最適な導入プランを相談する
この記事を書いた人
関連記事
-
 DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド
DifyのワークフローはYAMLで書ける Claude Codeで作成・修正・管理を完結させる実践ガイド -
Claude CodeのAIスキルをDifyワークフローへ自動変換する【Workflow as Code実践ガイド】
-
Human-in-the-Loopの活用事例 Difyでの具体的な運用パターン9選
-
【脱・OCR】Dify×VLMで、あらゆる画像・PDFを思い通りのJSONに変換する
-
Human-in-the-Loopの概念をDifyに落とし込み、AIの暴走を防ぐ安全設計を構築する
-
DifyのRAG精度を飛躍させる Contextual Retrieval構築マニュアル
-
RAG検索精度の革命|HyDEの理論からDify実装・検証まで完全解説
-
最先端のGraphRAGの技術をDifyに落とし込み、最高精度なRAGを構築する







