
【Dify】会話変数とコンテキストエンジニアリングを徹底的に深掘りチャットボットを最高品質に極める

はじめに
こんにちは!株式会社ノーコードソリューションズです。
LLM アプリケーション開発プラットフォーム Dify において、チャットボットの応答品質と運用コストは常にトレードオフの関係にあります。 単純に標準の「メモリ機能」を有効にするだけでは、会話が長引くにつれてトークン消費量が増大し、コストが嵩むだけでなく、不要な文脈が混入することで応答精度が低下するリスクも抱えることになります。
本記事では、Dify の会話変数とコンテキストエンジニアリングを徹底的に深掘り、最高品質のチャットボットを構築します。 基礎的な概念から、「JSONオブジェクトによる状態管理」や「文脈再構築」といった高度な応用テクニックまで、「旅行アシスタントBot」の実装例を交えながら、実践的なノウハウを網羅しました。
1. 会話変数とは
Difyの会話変数とは、1つの会話内で使用可能な「グローバル変数」です。
限定的な範囲でのみ有効なローカル変数とは対照的で、ワークフローの開始から終了まで存在し続けます。
Difyのフロー内で、特定の情報を抽出し、「変数」として保存・管理ができます。「文脈の保持」ができます。
2. 基礎編:メモリ機能と会話変数の違い
✅ LLMのメモリ機能
DifyのLLMには「メモリ機能」があります。
これは過去の会話を参照して回答を行うように設定できる機能です。
直近 N 件のやり取りを自動的に LLM のコンテキスト(プロンプト)に含めます。
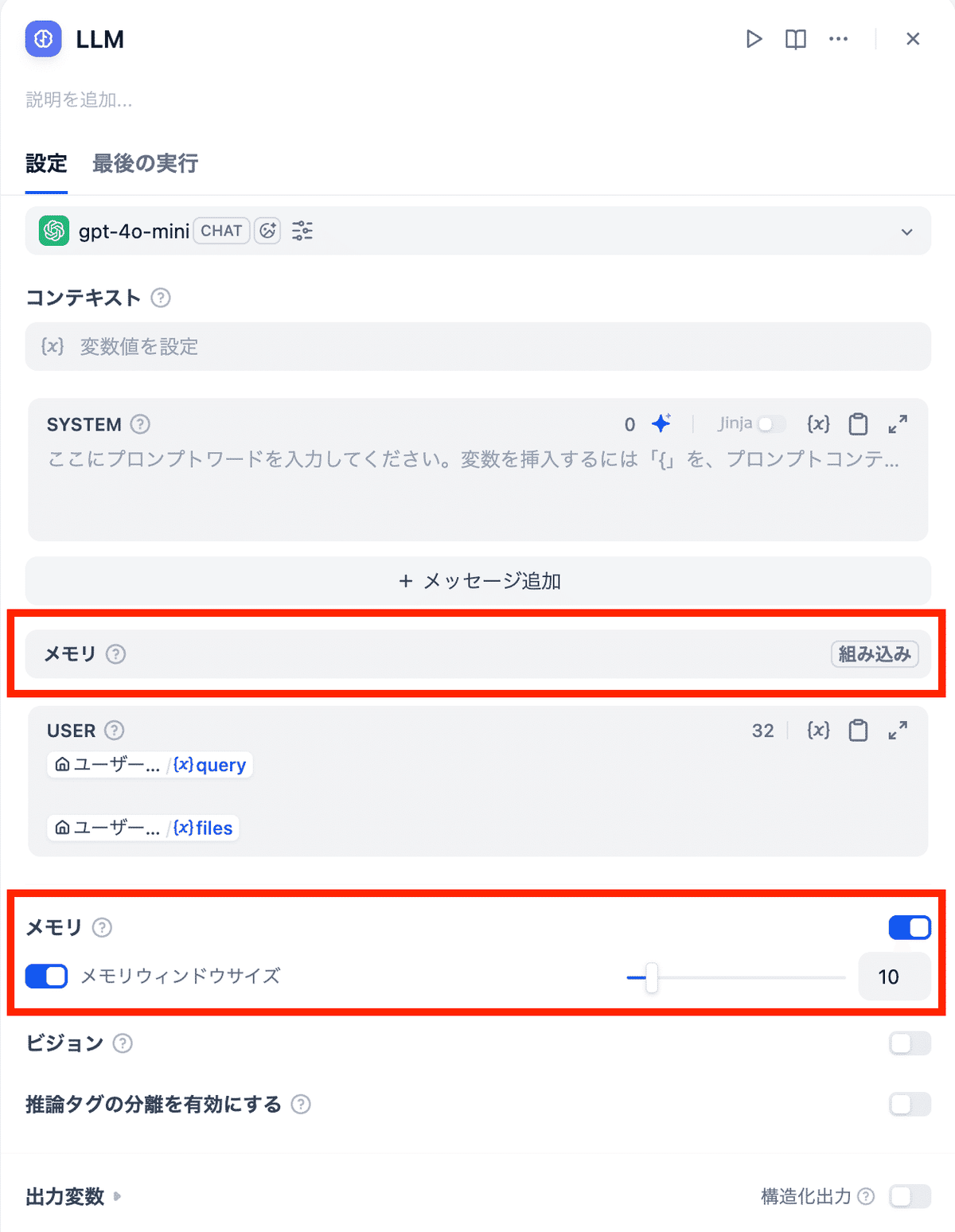
- メリット
- 設定が簡単:上記のボタンを操作するのみで、簡単に設定できます。
- 自然で連続的な会話:文脈を自動で考慮するため、連続的な自然な会話が可能です。
- デメリット
- トークン消費:メモリウィンドウサイズを設定しないと、トークン消費が激しくなります。
- 無駄な情報が入ってしまう:文脈を自動で考慮するため、無駄な情報も入ってしまいます。
✅会話変数
Difyのフロー内で、特定の情報を抽出し、「変数」として保存・管理ができます。「文脈の保持」が可能です。
必要な情報だけを「変数」として保存し、明示的にプロンプトに組み込みます。

- メリット
- 高精度:LLM に参照させたい情報を制御できるため、意図した回答を引き出しやすいです。
- トークン消費を抑えられる:必要な情報のみを送信するため、トークン効率が極めて高いです。
- 長期記憶:セッションが続く限り、古い情報でもピンポイントで取ってくることができます。
- デメリット
- 設計と実装の手間がかかってしまいます。
結論:高品質なチャットボットを目指すなら、会話変数の活用は必須と言えます。
3. 基礎編:会話変数の実装フロー
会話変数を導入するための基本ステップは以下の通りです。
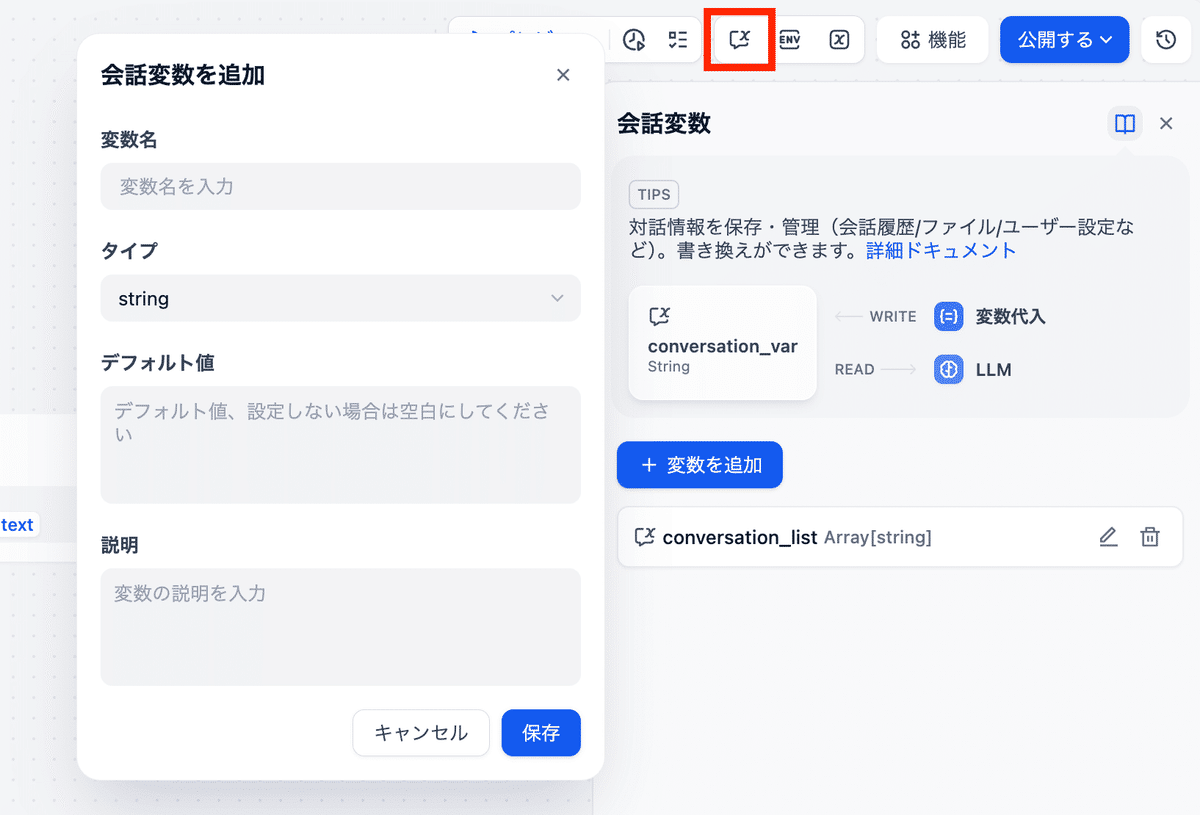
①変数の定義:画面右上の「会話変数」ボタンをクリックし、変数を追加します。
・名前:conversation_history(例)
・タイプ:Array[Object] や String(用途に応じて選択)
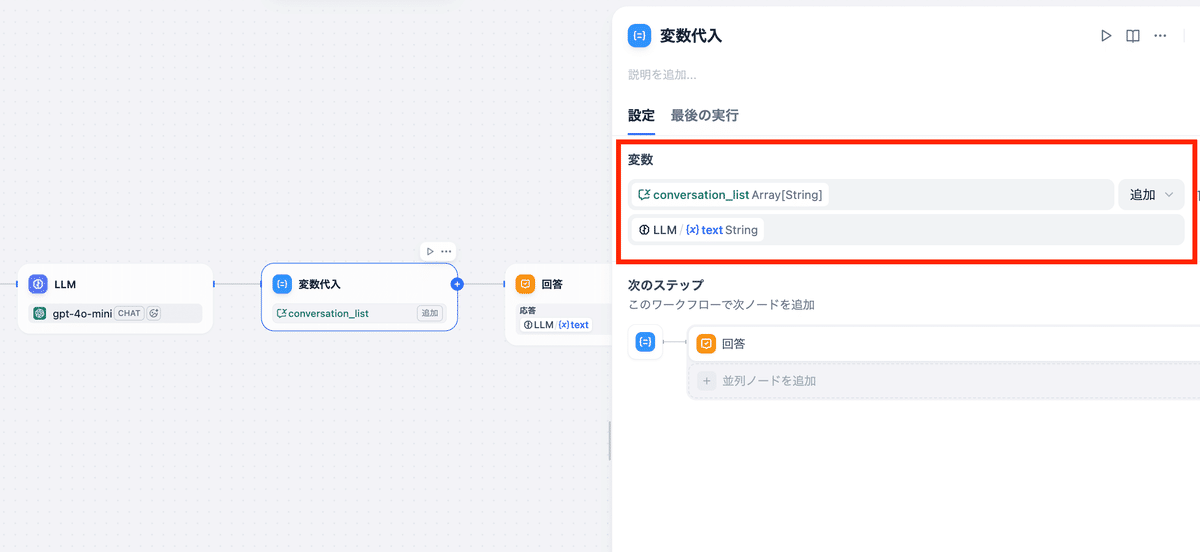
②変数への代入:LLM ノードの後続に「変数代入」ブロックを配置します。 ここで、LLM の出力やユーザーの入力を変数に追加・更新します。
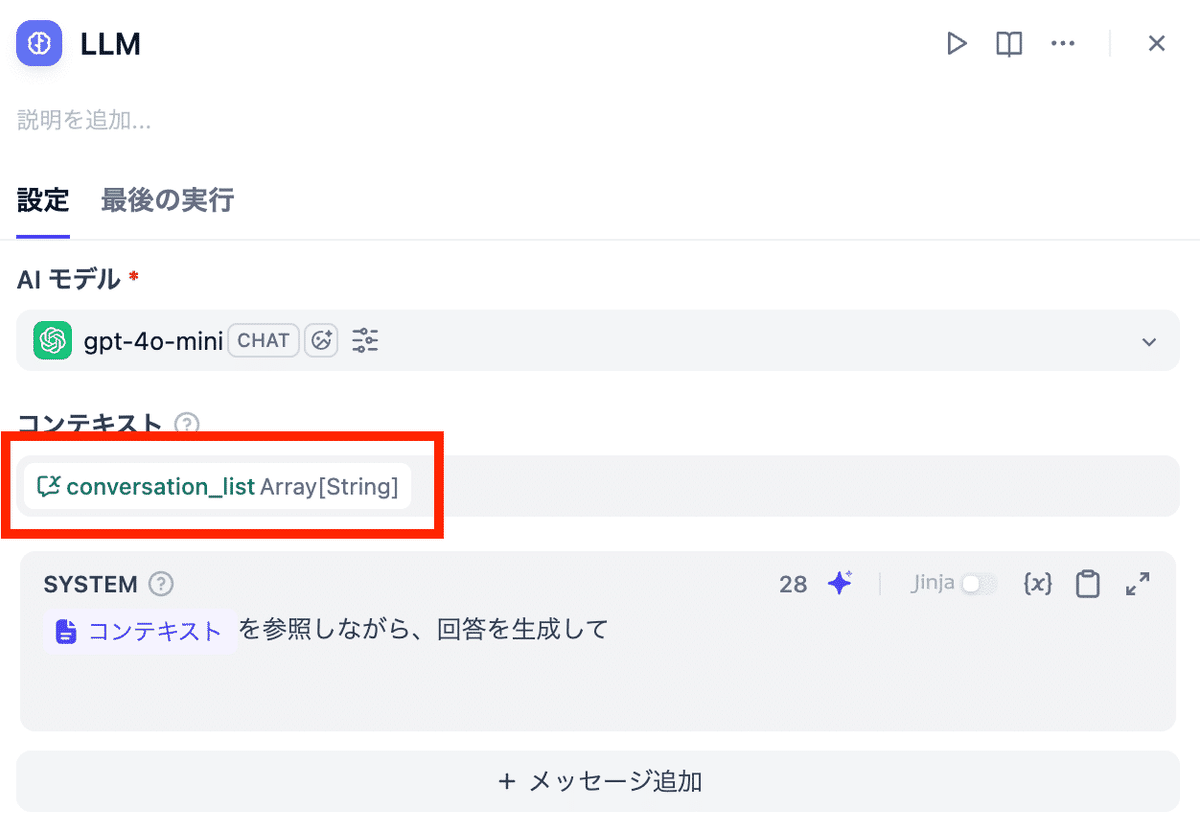
③変数の利用:LLM ノードの「コンテキスト」や「システムプロンプト」内で、定義した変数 {{conversation_history}} を参照します。
4. 実践編:自然な会話を実現する基本テクニック
単に変数をプロンプトに埋め込むだけでは不十分です。ここでは、実用レベルの品質を確保するための基本的な実装パターンを紹介します。
4-1. 構造化データによる履歴管理
会話履歴を単なるテキストの羅列として保存するのではなく、構造化データ(JSON配列)として管理します。 これにより、LLM は「誰が」「いつ」発言したかを明確に区別でき、文脈理解の精度が向上します。
推奨フォーマット:
[
{ "role": "user", "content": "箱根でいい宿ない?" },
{ "role": "assistant", "content": "どのような条件でお探しですか?" }
]4-2. スライディングウィンドウによるコスト管理
会話変数が無制限に増え続けるのを防ぐため、保持する履歴の上限(ウィンドウサイズ)を設定します。 例えば「最新の10ターンのみ保持する」といったロジックをコードノードで実装することで、トークンコストを予測可能な範囲に制御できます。
def main(history: list, new_user_input: str, new_assistant_output: str) -> dict:
"""
履歴の上限を管理し、最新の状態を維持する関数
MAX_TURNS: 保持するやり取りのペア数
"""
MAX_TURNS = 5 # ユーザー発言 + アシスタント発言 で 1セット x 5 = 10メッセージ
# 新しいエントリの作成
new_entries = [
{"role": "user", "content": new_user_input},
{"role": "assistant", "content": new_assistant_output}
]
# 履歴の結合
updated_history = history + new_entries
# スライディングウィンドウ処理
# 1セット(2メッセージ)単位で計算
if len(updated_history) > MAX_TURNS * 2:
# 超過分を先頭から削除 (スライス)
updated_history = updated_history[-(MAX_TURNS * 2):]
return {
"result": updated_history
}5. 応用編:JSONオブジェクトによる状態管理
ここからは、より複雑なタスク(例:旅行アシスタント)をこなすための応用テクニックです。 変数の数が数十個に増えるような複雑なBotでは、変数を個別に定義するのではなく、JSONオブジェクトでまとめて管理するのがベストプラクティスです。
5-1. 状態オブジェクトの設計
「目的地」「予算」「フラグ」などを個別の変数にせず、ひとつのオブジェクト変数(例:travel_session)にまとめます。
// travel_session の中身のイメージ
{
"filters": {
"hotel": { "has_onsen": true, "max_price": 30000 },
"sightseeing": { "category": "history" }
},
"intent": {
"search_hotel": true,
"search_spot": false
},
"keys": {
"destination": "箱根",
"keywords": ["露天風呂", "懐石料理"]
}
}5-2. LLMによる一括更新
ユーザーの入力を分析するノードを作成し、JSON Schema を使って、一度にすべての状態フラグや抽出キーワードを出力させます。
プロンプト例:
ユーザーの入力から以下の情報を抽出してください。
1. ホテル検索フラグ(true/false)
2. 目的地や条件のキーワード
出力は必ず指定の JSON Schema に従ってください。これにより、1回のLLM呼び出しで複数の状態を更新でき、応答速度とコストの両面で有利になります。
6. 堅牢性向上:コードノードによる「正規化」
LLMが出力したJSONをそのまま後続の処理で使うと、構造が崩れていた場合にエラーになります。 Difyのコードノードを挟むことで、データの正規化とデフォルト値の注入を行います。
コードノードの実装例(JavaScript):
function main({ ic_text }) {
let data = {};
try {
const s = (ic_text ?? "").toString().trim();
data = s ? JSON.parse(s) : {};
} catch (e) {
data = {};
}
// フラグの確定(なければデフォルト値 false)
const intent = data.intent || {};
let need_hotel = intent.search_hotel === true ? 1 : 0;
// 目的地の抽出(なければ空文字)
const keys = data.keys || {};
let destination = keys.destination || "";
return { need_hotel, destination };
}このように「型保証」をすることで、ワークフローが予期せぬエラーで止まるのを防げます。
7. RAG精度向上のカギ:Context Refinement(文脈再構築)
RAGを行う際、ユーザーが「そこの予算感は?」のように指示語を使うと、単純なキーワード検索では正しいドキュメントがヒットしません。 会話変数に保存された「制約条件」を使って、検索クエリを完全な文に書き換える(Refine)テクニックが極めて有効です。
仕組み
- 会話変数に、これまでの会話で確定した条件(例:目的地=箱根, 条件=露天風呂付き)を保持しておく。
- Context-Refinement (LLM) ノードを用意する。
- ユーザーの質問と変数の内容をあわせて、「検索用の完全な質問文」を生成させる。
プロンプト例:
【現在の制約条件】{"destination":"箱根", "condition":"露天風呂付き客室"}
【ユーザーの質問】「そこは一泊いくらくらい?」
## 指示
制約条件から具体的な内容を補完し、単体で意味が通る自然な一文に書き換えてください。
## 出力例
箱根にある露天風呂付き客室のある旅館の、一泊あたりの平均価格はいくらですか?こうして生成された「リッチな検索クエリ」を知識検索ノードに入力することで、RAGの検索精度が劇的に向上します。
8. 足りない情報を聞き返す
必要な情報が揃っていない状態で無理に回答生成に進むと、ハルシネーションの原因になります。 会話変数の充足状況をチェックし、足りない場合だけ「聞き返し」を行うループを作ります。
- 聞き返しノード
- 「現在特定できている情報」と「ユーザーの質問」を比較。
- 不足している場合、「具体的な人数はお決まりですか?」といった質問を生成してユーザーに返す。
- 不足がない場合のみ、次の検索ステップへ進む。
まとめ
Difyの会話変数は、単なる「値の保存場所」ではありません。 コードノードによる処理やLLMによる文脈のContext-Refinementと組み合わせることで、アプリケーションの「状態」を管理し、記憶を持つ高度なエージェントを構築するための強力なバックボーンとなります。
- 構造化: 関連する変数はJSONオブジェクトでまとめる。
- 正規化: LLMの出力をCodeノードで検証・整形する。
- 再構築: 過去の文脈(変数)を使って、RAG検索クエリを最適化する。
これらのテクニックを取り入れることで、Difyで作るチャットボットは「ただ応答するだけ」から「ユーザーの意図を深く理解し、的確にタスクを遂行するパートナー」へと進化します。ぜひ試してみてください。
この記事を書いた人
関連記事
-
 AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価
AI時代の構造化データの置き方|情シスのためのガバナンスとPoC評価 -
Claude Code・Codexに機密情報を入れて大丈夫?情シスのためのセキュリティ設計ガイド
-
Claude Code GitHub Actionsでレビュー工数を削減した話 〜情シス・開発リーダーのためのチーム導入とセキュアCI設計〜
-
Microsoft Listsで脱・共有Excel。「壊れる・被る・履歴不明」を防ぐ移行手順を実演
-
AIの構造化データとは?図面・帳票を「AIが使える形」に変える全手法
-
【EDI 2024年問題】製造業のEDIツール完全ガイド|選定5観点とAI連携まで情シス向けに徹底解説
-
Hooksを活用してClaude Codeの処理制御に正解を出してみる
-
【セキュリティ】 プロンプトインジェクションの対策方法を徹底解説する







